
List
Search
1. Preface
1.1. 도메인 주도 설계

이 책에서 제시하는 설계 방식은 대부분 “책임 주도 설계(Responsibility-Driven Design)”의 원칙을 따르는데,
책임 주도 설계는 ‘Designing Object-Oriented Software’에서 제안되어 ‘Object Design’에서 새롭게 바뀌었다.
또한 이 책의 설계 방식은 ‘Object-Oriented Software Construction’에서 설명하고 있는 “계약에 의한 설계(Design By Contract)”에 크게 의존하고 있기도 하다(특히 3부의 주된 내용이다).
그리고 ‘Applying UML and Patterns’과 같은 책에서 설명하고 있는 것과 더불어, 기타 널리 받아들여 지고 있는 객체지향 설계에 관한 베스트 프랙티스와도 일반적인 배경에 있어 일관됨을 유지하고 있다.
•
책임주도 설계를 바탕으로 기능 요구사항을 녹임
•
계약에 의한 설계(DBC)를 바탕으로 불변식을 녹임
1.2. DDD에서의 기능 구현
•
기능 요구사항과 불변식을 애그리거트로 구현
•
애그리거트 = 기능 요구사항 + 불변식
1.3. 불변식
•
언제나 일관되게 유지돼야하는 비즈니스 규칙
•
불변식은 트랜잭션 일관성(Transactional Consistency)와 관련
2. 애그리거트
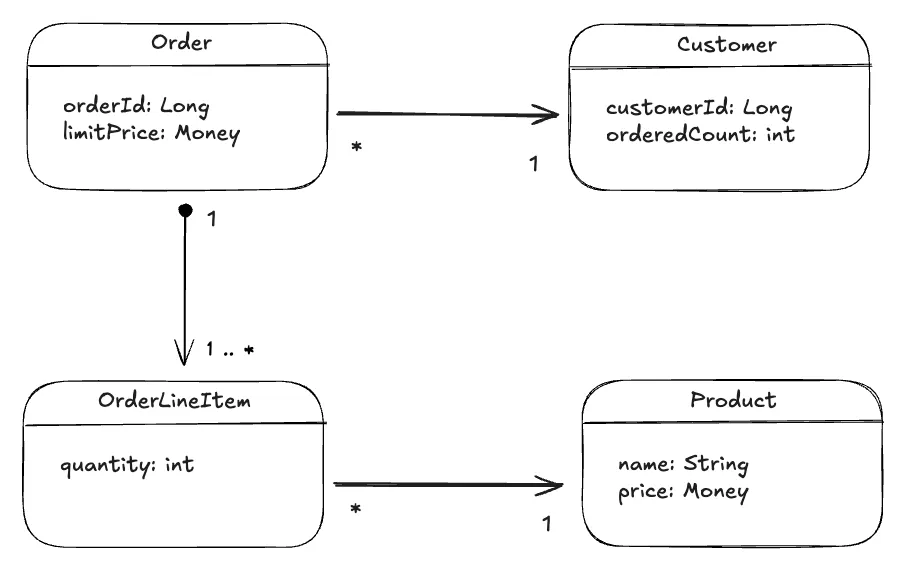
2.1. 주문 도메인 모델 예제
불변식 - Order의 총 금액은 Order의 limitPrice보다 같거나 작아야한다.
•
도메인 모델
•
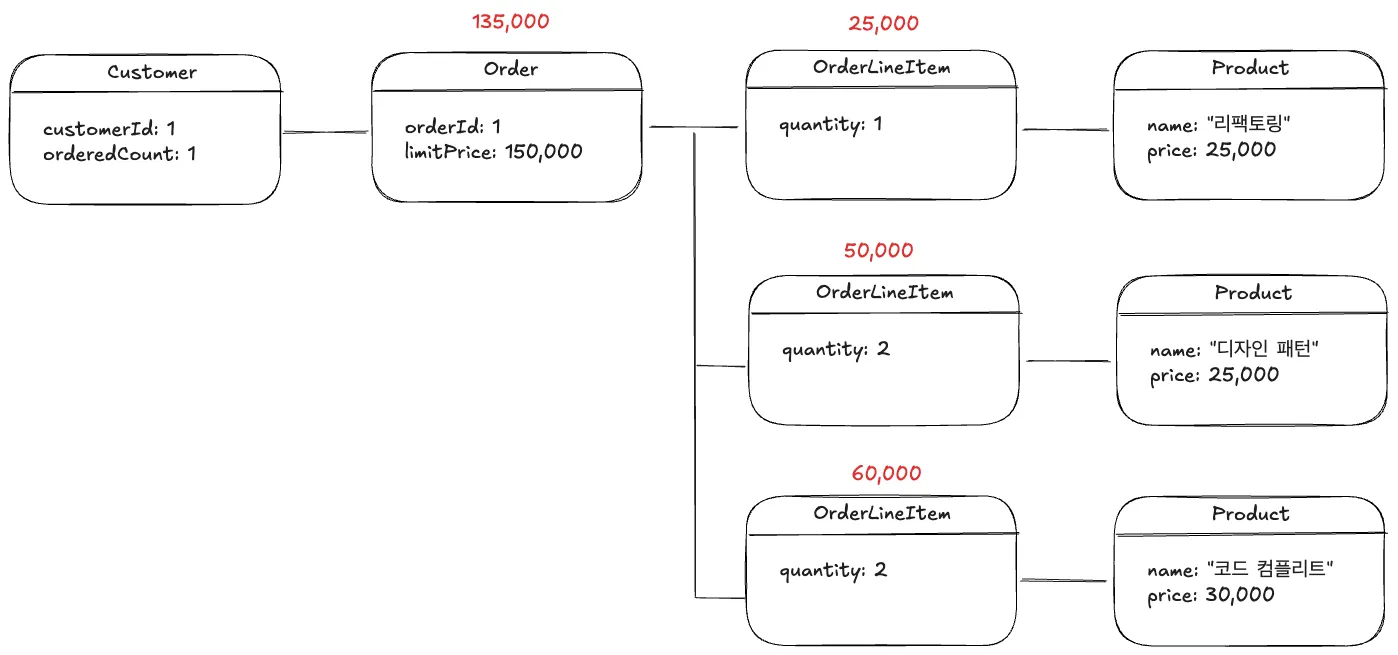
불변식 만족
◦
OrderLineItem의 총 금액의 합 (135,000)이 Order의 limitPrice (150,000) 보다 같거나 작음
2.2. 불변식 위반
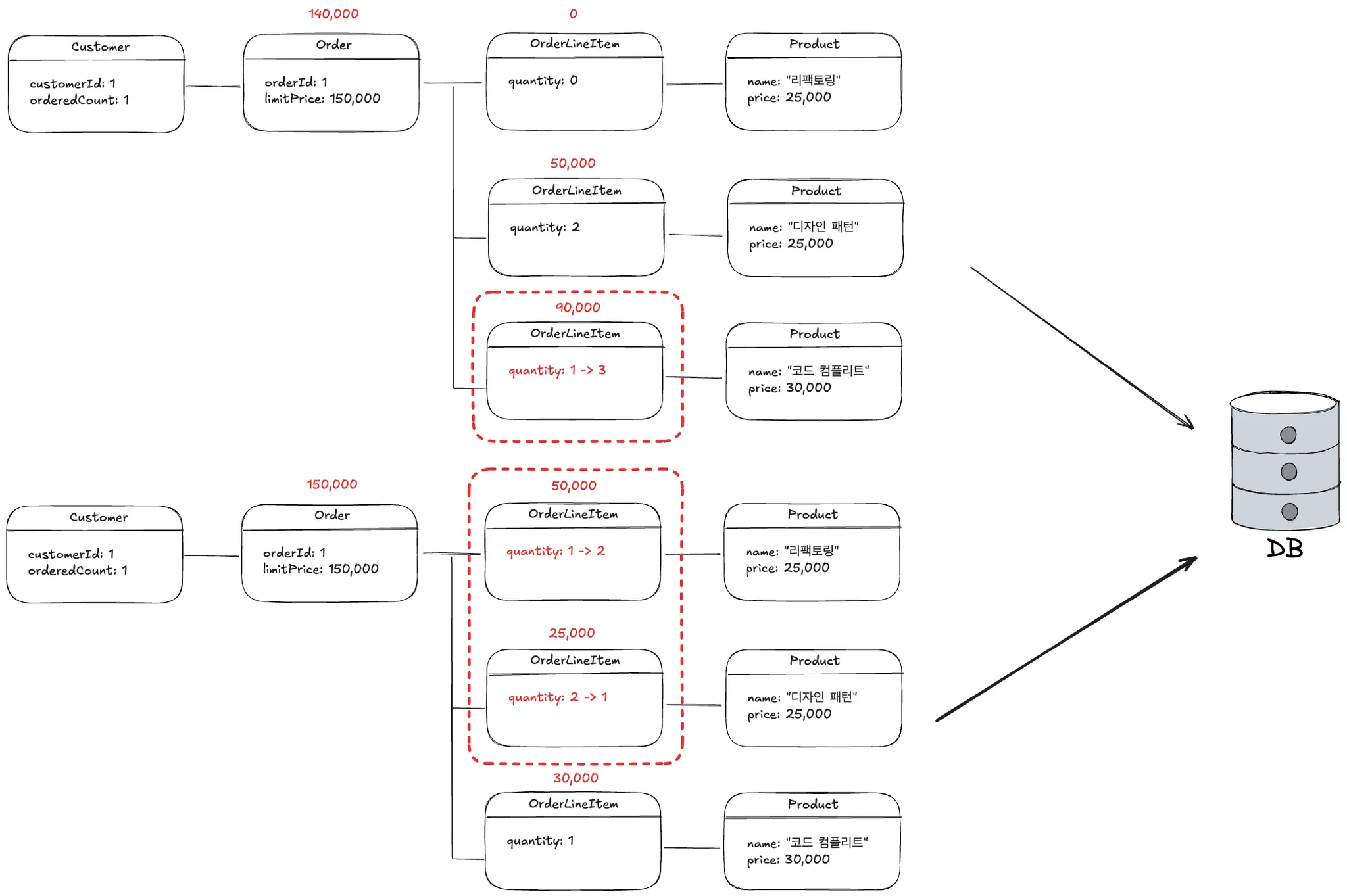
2.2.1. 수정된 OrderLineItem만 저장할 경우
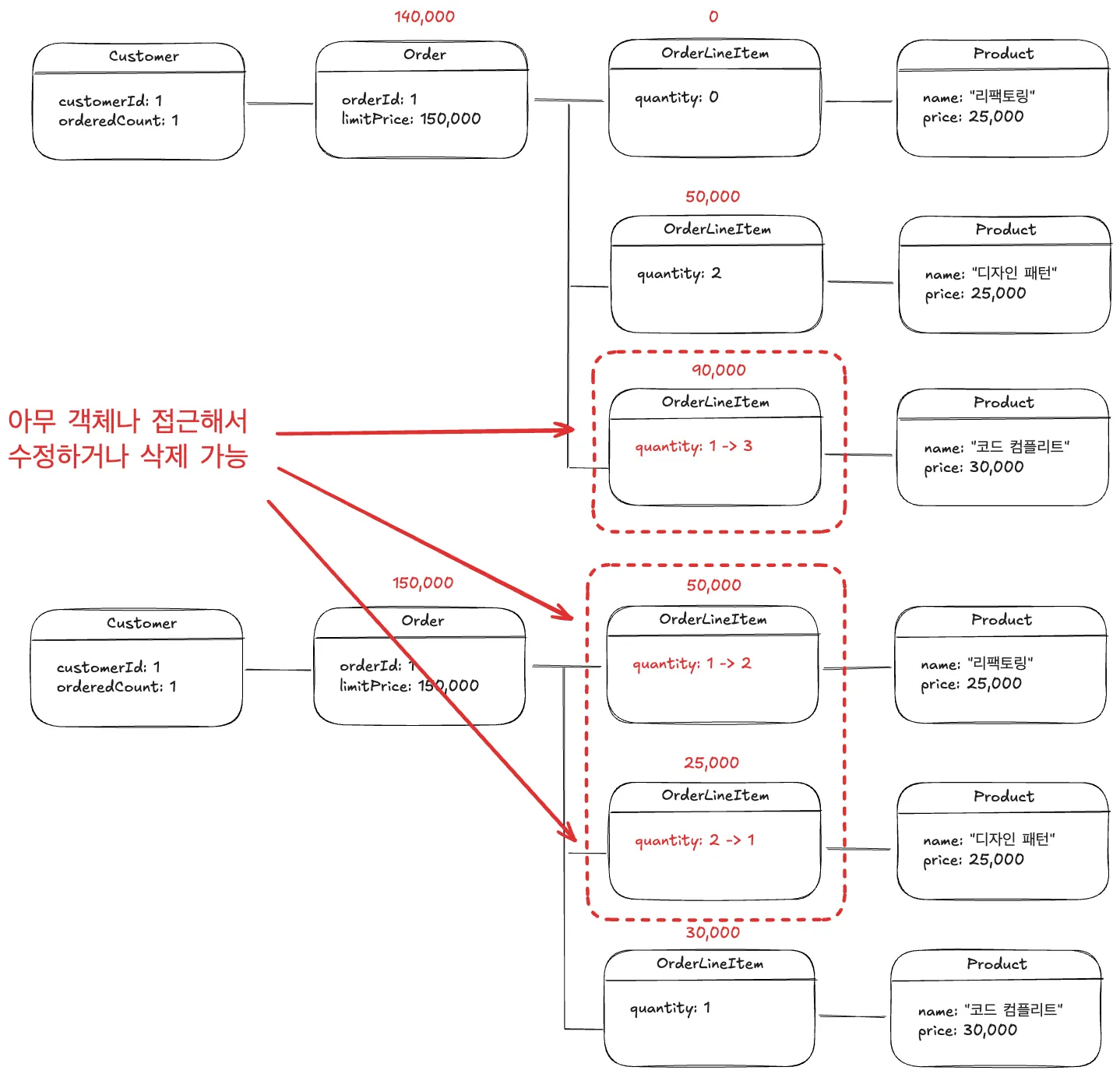
•
서로 다른 두개의 요청이 동시에 OrderLineItem을 수정하는 경우
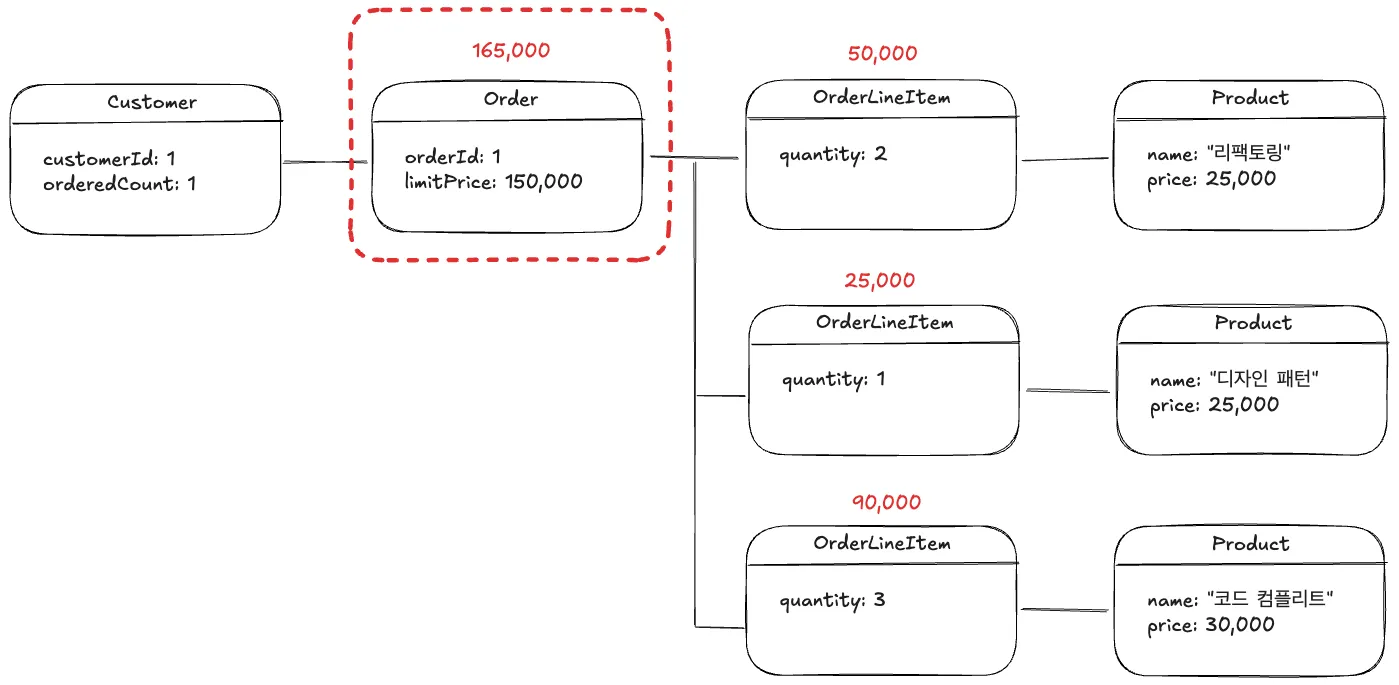
2.2.2. 불변식 위반
•
OrderLineItem의 총 금액의 합 (165,000)이 Order의 limitPrice (150,000) 보다 같거나 작음
•
문제의 원인
2.3. 애그리거트
우리는 경합이 높은 지점을 느슨하게 하고, 엄격한 불변식을 보다 엄격하게 지켜지게 하는 모델을 찾아야 한다.
비록 이러한 문제가 데이터베이스 트랜잭션과 관련된 기술적 문제로 나타나더라도 문제의 근원은 모델에 경계가 정의되어있지 않다는 데 있다.
먼저 우리는 모델 내의 참조에 대한 캡슐화를 추상화시킬 필요가 있다.
AGGREGATE는 우리가 데이터 변경의 단위로 다루는 연관 객체의 클러스터를 말한다.
•
모델 내의 참조에 대한 캡슐화를 추상화
◦
묶어서 밖에서 못보게 하기 위해
◦
의존성의 경계를 도메인에서 찾아라
•
코드의 유지보수를 잘하고 싶기 위해 코드의 경계를 결정
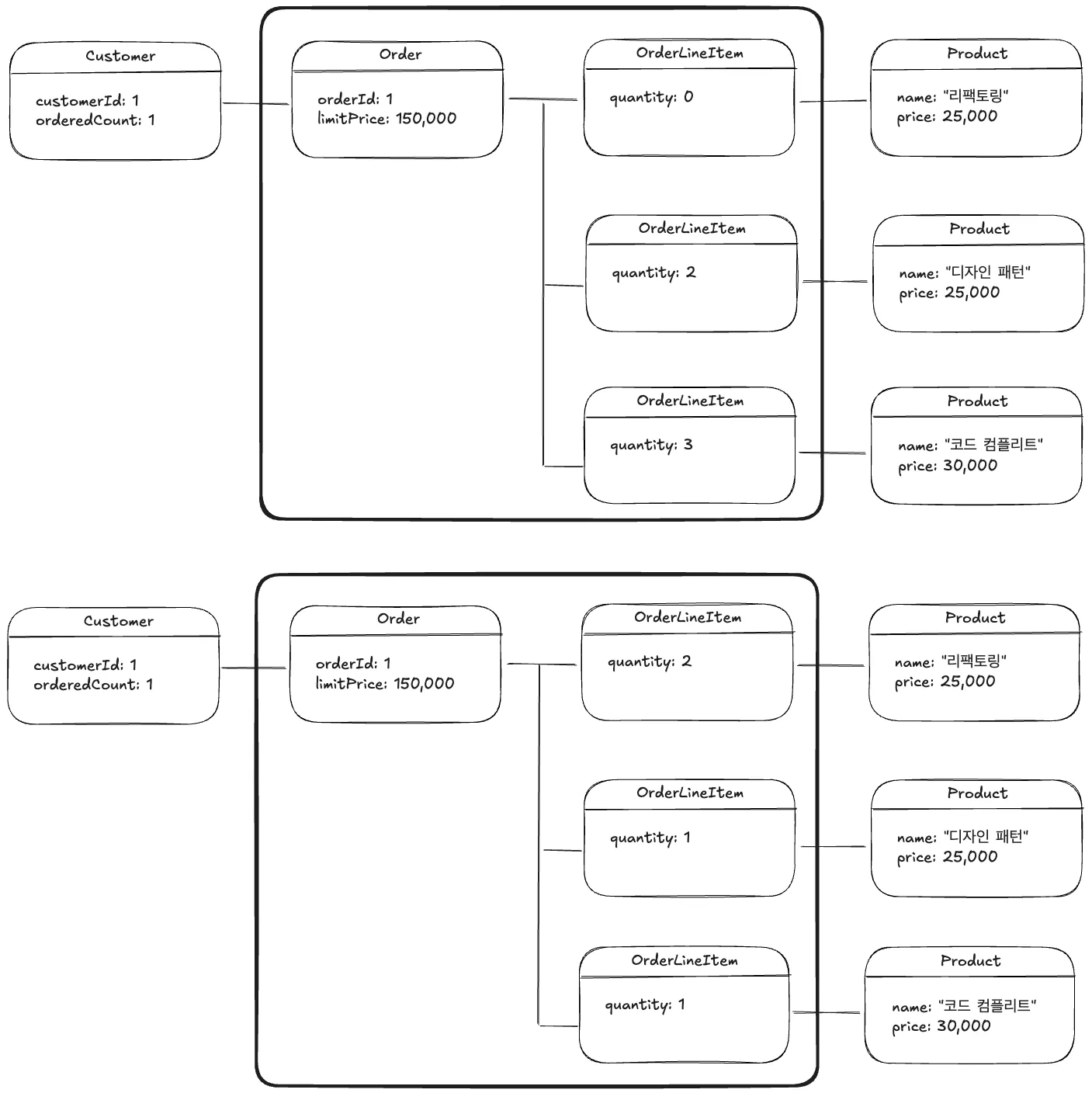
2.3.1. 경계 정의 및 경계 내부 접근 통제
•
특정 객체를 통해서만 내부의 객체 접근 허용
◦
예) Order 객체를 통해서만 OrderLineItem 접근 허용
•
경계는 어떻게 잘 정의할 수 있나?
◦
결국 도메인 / 요구사항을 잘 분석해봐야 함
2.3.2. 루트와 식별성
각각의 AGGREGATE에는 루트(root)와 경계(boundary)가 있다.
경계는 AGGREGATE에 무엇이 포함되고 포함되지 않는지를 정의한다.
루트는 단 하나만 존재하며 AGGREGATE에 포함된 특정 ENTITY를 가리킨다.
비록 경계 안의 객체들은 서로 참조할 수 있지만, 경계 바깥의 객체들은 해당 AGGREGATE의 구성요소 중 루트만 참조할 수 있다.
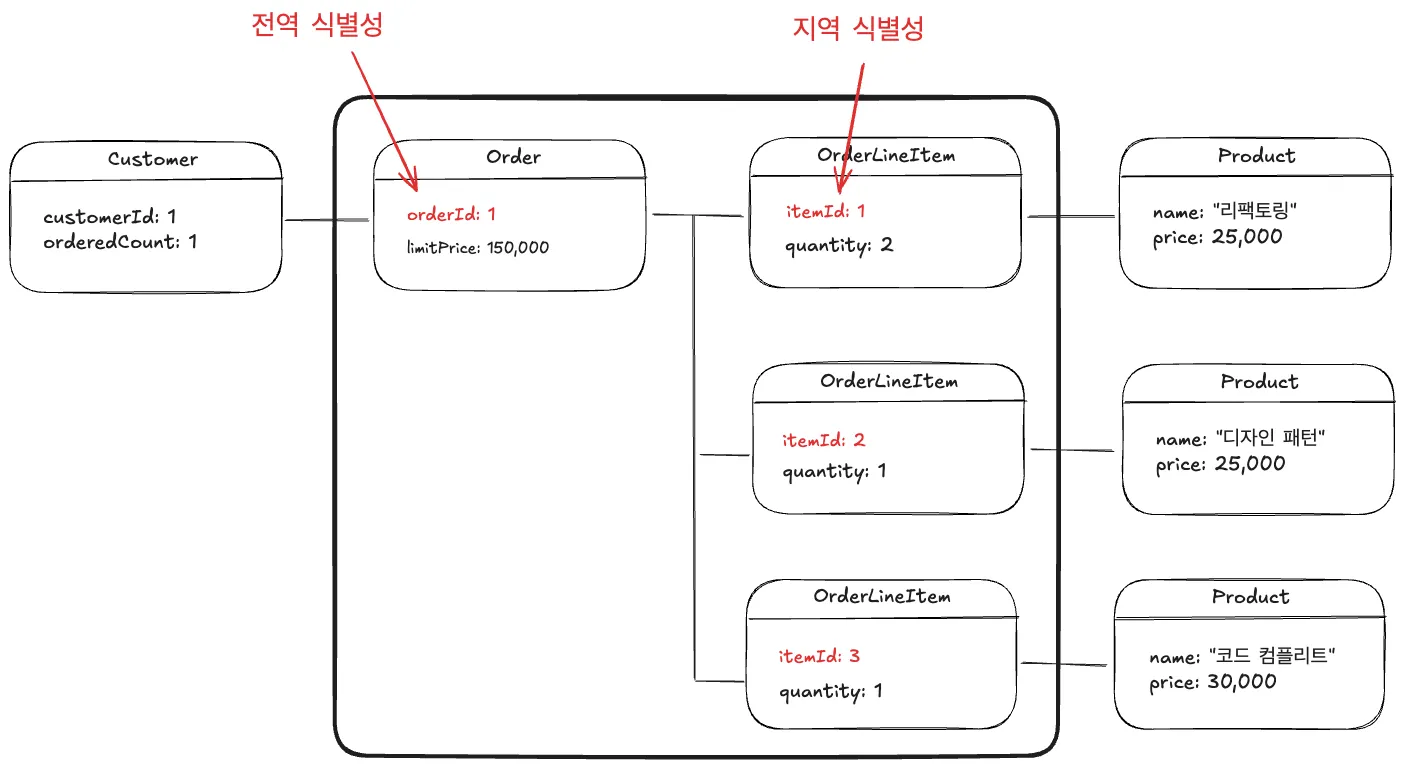
•
외부에서는 애그리거트 루트만 접근 가능
•
전역 식별성
◦
외부에서 접근하기 위해 전역적으러 구분 가능한 식별자 (애그리거트의 식별자)
•
지역 식별성
◦
애그리거트 루트에 의해서만 접근하므로 내부에서만 구분 가능한 식별자 (하위 도메인의 식별자)
2.3.3. 애그리거트와 불변식
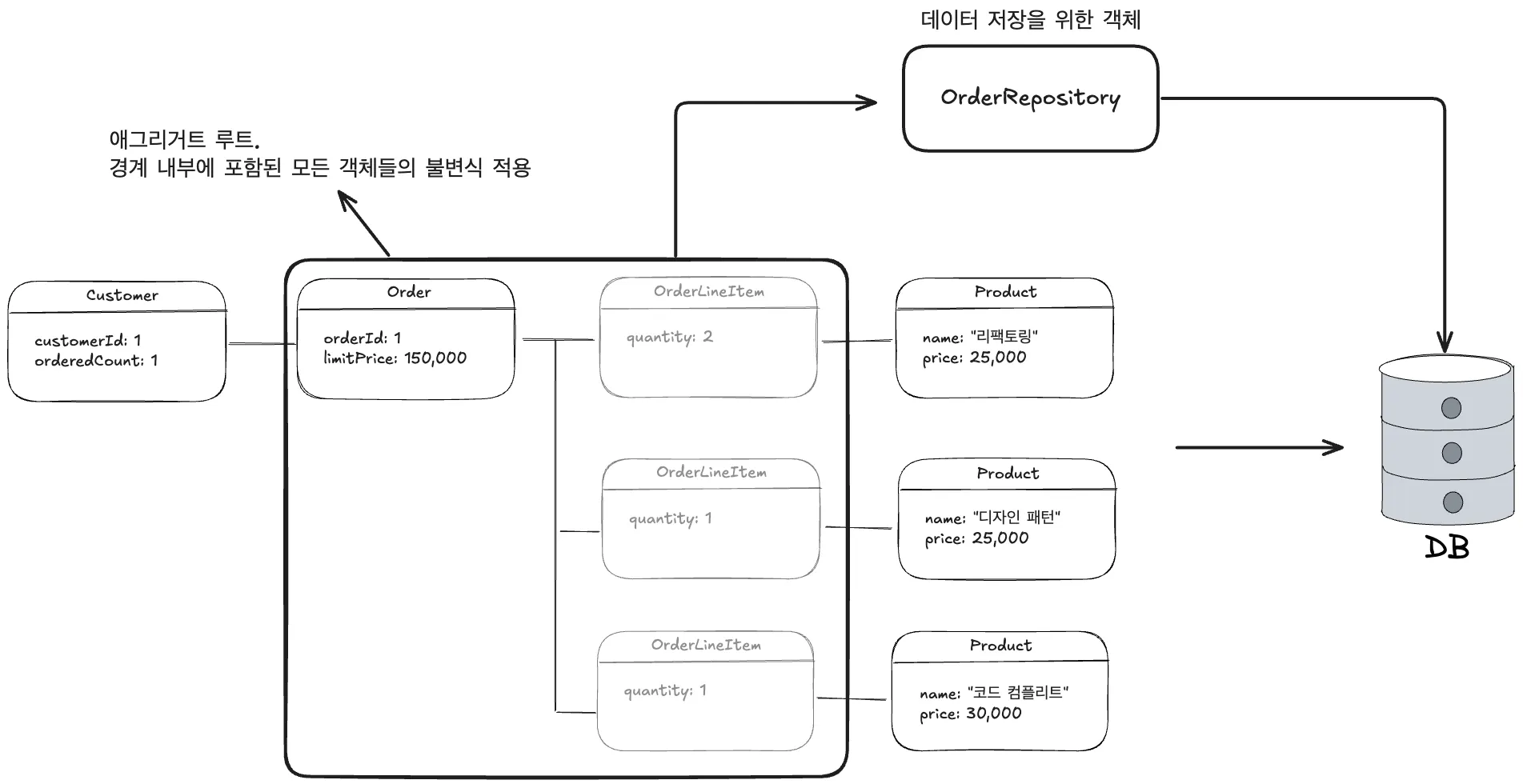
내부 구성 요소에 대한 일시적인 참조는 단일 연산에서만 사용할 목적에 한해 외부로 전달될 수 있다.
루트를 경유하지 않고는 AGGREGATE의 내부를 변경할 수 없다.
이런 식으로 AGGREGATE의 각 요소를 배치하면 AGGREGATE안의 객체와 전체로서의 AGGREGATE의 상태를 변경할 때 모든 불변식을 효과적으로 이행할 수 있다.
•
불변식을 만족하는 로직을 넣어라!
•
애그리거트 전체에 걸쳐서 불변식을 녹여라 → 불변식을 기준으로 애그리거트 경계가 정의 됨
•
애그리거트는 트랜잭션과 데이터 저장/조회의 단위가 됨
•
데이터 저장을 위한 객체 → 레파지토리
•
여담
◦
애그리거트를 처음부터 잘 잡는것에 집착하지 말자
◦
처음부터 잘 잡긴 어렵다.
3. 레파지토리와 연관관계
3.1. 레파지토리
전역적 접근을 요하는 각각의 객체 타입에 대하여, 메모리상에 해당 타입의 객체로 이루어진 컬렉션이 있다는 착각을 불러 일으키는 객체를 만들어라.
... 객체를 추가하고 제거하는 메서드를 제공하고, 이 메서드가 실제로 데이터 저장소에 데이터를 추가하고 데이터 저장소에서 제거하는 연산을 캡슐화하게 하라.
실질적으로 직접 접근해야 하는 AGGREGATE의 루트에 대해서만 REPOSITORY를 제공하고, 모든 객체 저장과 접근은 REPOSITORY에 위임하여 클라이언트가 모델에 집중하게 하라.
•
애그리거트 단위로 리포지토리 추가
•
라이프사이클(생명주기) 관리
•
레파지토리를 잘 이해하기 위해서는 연관관계의 개념과 활용 방법 이해 필요
3.2. 연관관계 단순화
•
객체간의 관계가 설정되어있다면, 연관된 객체에 접근할 수 있다는 것을 의미함. 이는 탐색가능하다는 것을 의미
•
연관관계는 단순화하는 것이 좋음
1.
탐색 방향 부여
2.
다중성 줄이기
3.
불필요한 연관관계 제거
•
cf) 연관관계는 어떻게 묶고 분리할 것인가?
◦
함께 생성되고 함께 삭제되는 객체들을 묶어라
◦
도메인 제약사항을 공유하는 객체들을 함께 묶어라
◦
가능하면 분리해라
3.2.1. 탐색방향 부여
•
현업에서 연관관계가 양방향으로 구현되어있어서 생각보다 많이 꼬임
•
탐색방향 부여
◦
양방향 X
◦
단방향 O
•
단방향 설정이 어려움
◦
도메인 관점에서는 모든게 양방향
◦
일부가 어색하더라도 단방향을 정해서 가야함
class A {
private B b;
public void setB(B b) {
this.b = b;
this.b.setA(this);
}
}
class B {
private A a;
public void setA(A a) {
this.a = a;
}
}
Java
복사
양방향 관계
class A {
private B b;
public void setA(B b) {
this.b = b;
}
}
class B {
}
Java
복사
단방향 관계
3.2.2. 다중성 줄이기
•
일반적으로 1:N 보다는 N:1이 훨씬 나음
◦
예) 주문과 사용자
◦
사용자(1)에서 주문(N)을 모두 참조하지 않음
◦
각각 도메인이 유저 도메인을 참조하지, 유저 도메인이 다른 도메인들을 다 갖고오진 않음
•
1:N 관계로 성능이슈로 발생하는건 방향이 잘못 선택된 것
class A {
private Collection<B> bs;
}
class B {
}
Java
복사
class A {
}
class B {
private A a;
}
Java
복사
•
M:N 관계 (다대다)
◦
A와 B 테이블이 M:N 관계이고 중간 테이블인 C가 있는 경우
◦
단방향 설정
▪
A에서 중간테이블을 통해 B를 조회하게 구현
class A {
private Map<C, B> as;
B get(C c) {
// 특정 C 객체에 대한 B 반환
}
}
class B {
}
Java
복사
•
M:N 관계 TypeORM 버전
import { Entity, PrimaryGeneratedColumn, ManyToMany, JoinTable } from 'typeorm';
import { B } from './B';
import { C } from './C';
@Entity()
export class A {
@PrimaryGeneratedColumn()
id: number;
// A와 B는 C를 통해 다대다 관계를 가짐
@ManyToMany(() => B)
@JoinTable({
name: 'a_c_b', // 중간 테이블 이름
joinColumn: { name: 'a_id', referencedColumnName: 'id' }, // A 테이블과 연결된 열
inverseJoinColumn: { name: 'b_id', referencedColumnName: 'id' } // B 테이블과 연결된 열
})
bs: B[];
// 특정 C 객체에 대해 B를 반환하는 메서드
getB(c: C): B | undefined {
// 여기서는 단순히 임의의 B 객체를 반환한다고 가정
return this.bs.find(b => /* b와 c의 관계 조건 */);
}
}
TypeScript
복사
import { Entity, PrimaryGeneratedColumn } from 'typeorm';
@Entity()
export class B {
@PrimaryGeneratedColumn()
id: number;
// 추가 필드나 메서드는 필요에 따라 추가 가능
}
TypeScript
복사
import { Entity, PrimaryGeneratedColumn, ManyToMany, JoinTable } from 'typeorm';
import { A } from './A';
import { B } from './B';
@Entity()
export class C {
@PrimaryGeneratedColumn()
id: number;
@ManyToMany(() => A)
@JoinTable({
name: 'a_c_b',
joinColumn: { name: 'c_id', referencedColumnName: 'id' },
inverseJoinColumn: { name: 'a_id', referencedColumnName: 'id' }
})
as: A[];
@ManyToMany(() => B)
@JoinTable({
name: 'a_c_b',
joinColumn: { name: 'c_id', referencedColumnName: 'id' },
inverseJoinColumn: { name: 'b_id', referencedColumnName: 'id' }
})
bs: B[];
}
TypeScript
복사
3.2.3. 불필요한 연관관계 제거
•
제일 좋은 방법
•
연관관계가 불필요하다면 제거하라
3.3. 연관관계와 탐색가능성
•
연관관계는 한 객체를 통해 다른 객체에 다을 수 있음을 의미
3.3.1. 객체 참조를 통한 탐색 (강한 결합도)
•
Order 인스턴스 안에 포함된 속성을 통해 Shop 인스턴스로 직접 이동
◦
Order.shop
public class Order {
private Shop shop;
}
public class Shop {
private Long id;
}
Java
복사
3.3.2. 제3의 객체를 통한 탐색 (약한 결합도)
•
Repository (제3의 객체)를 통해 연관관계 해결
public class Order {
private Long shopId;
}
public class Shop {
private Long id;
}
Shop shop = thirdPartyObject.findBy(order.getShopId());
Java
복사
3.4. 레파지토리와 애그리거트
Customer 객체가 주문이 이루어진 모든 Order에 대한 컬렉션을 갖고 있어야 하는가?
아니면 Customer ID 필드에 대한 검색을 통해 데이터베이스에서 Order를 찾아야 하는가?
검색과 연관을 알맞게 조합하면 설계를 이해하기 쉬워진다.
3.4.1. 애그리거트 내부 → 객체 참조
•
10번 중에 7번을 쓰고 3번은 안쓴다면 차라리 애그리거트로 안묶는게 나을 수 있다
•
애그리거트 내부는 객체 참조를 통해 탐색
◦
Order과 OrderLineItem은 강결합
◦
항상 같이 다님
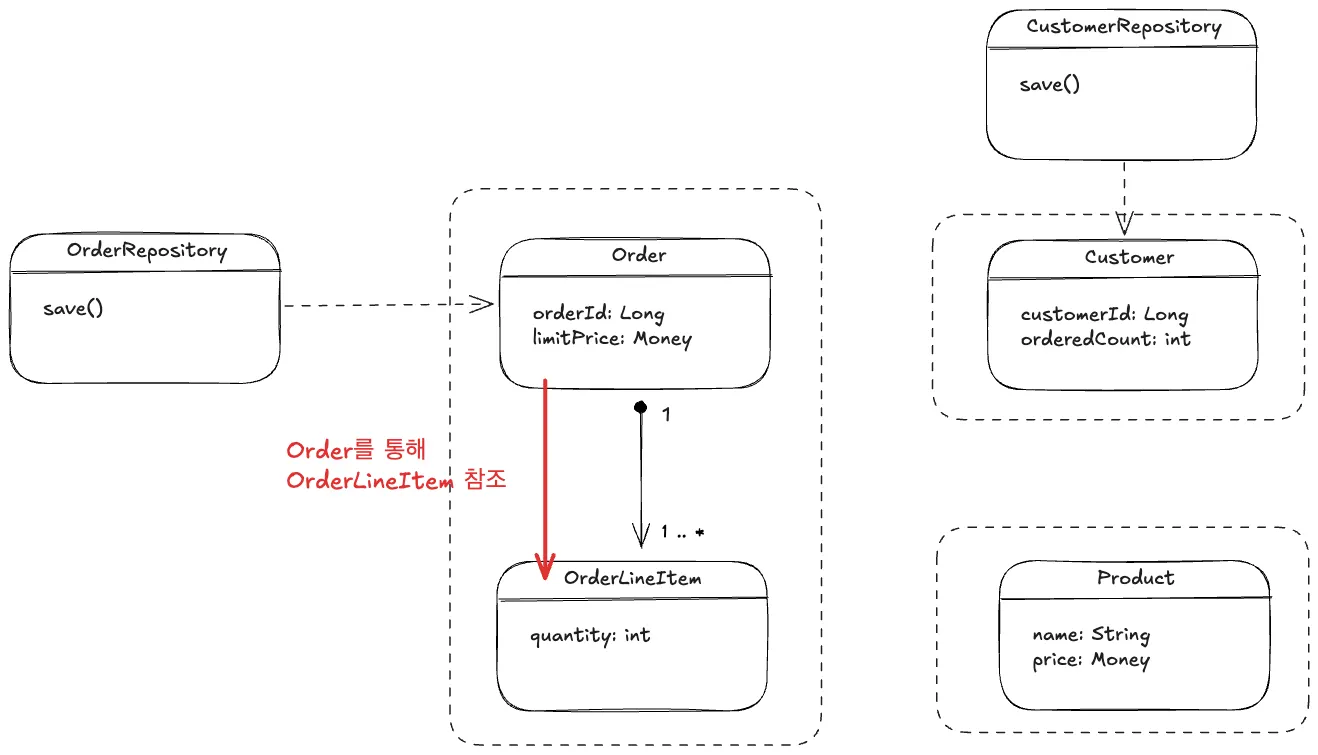
3.4.2. 애그리거트 외부 → 레포지토리를 통해 탐색
•
복잡성 감소를 위해 ID를 이용해 참조
•
필요할때 가져와 → 리포지토리를 통해 조회
◦
연관관계
•
리포지토리
◦
애그리거트와 애그리거트 사이를 연결해줌
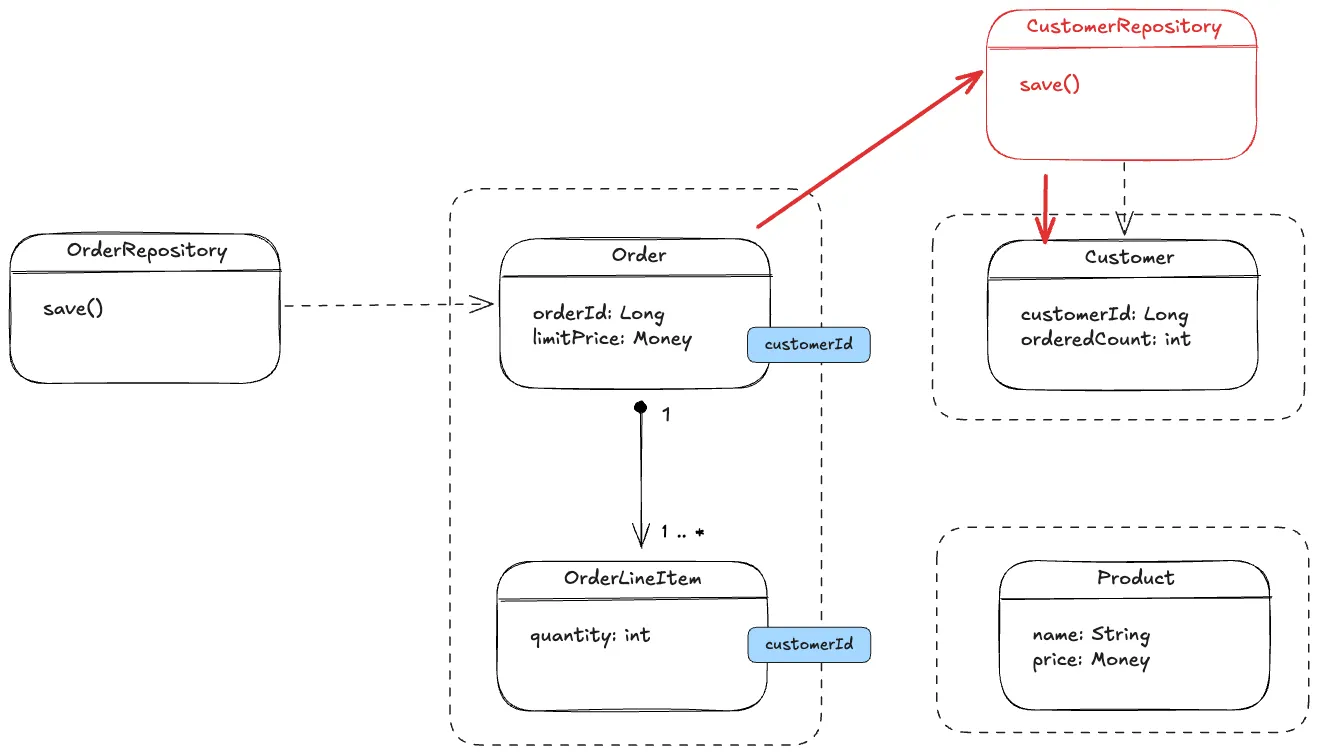
4. 애그리거트 정리
이제 그러한 개념적 AGGREGATE를 구현하기 위해서는 모든 트랜잭션에 적용되는 다음과 같은 규칙이 필요하다.
•
루트 ENTITY는 전역 식별성을 가지며 궁극적으로 불변식을 검사할 책임이 있다.
•
각각의 루트 ENTITY는 전역 식별성을 가진다. 경계 안의 ENTITY는 지역 식별성을 지니며, 이러한 지역 식별성은 해당 AGGREGATE 안에서만 유일하다.
•
AGGREGATE의 경계 밖에서는 루트 ENTITY를 제외한 AGGREGATE 내부 구성요소를 참조할 수 없다.
•
지금까지의 규칙을 바탕으로 결론을 내려보면
◦
데이터베이스 질의를 이용하면 AGGREGATE의 루트만을 직접적으로 획득할 수 있다.
◦
다른 객체는 모두 AGGREGATE를 탐색하여 발견해야 한다.
•
AGGREGATE 안의 객체는 다른 AGGREGATE의 루트만을 참조할 수 있다.
•
삭제 연산은 AGGREGATE의 경계 안의 모든 요소를 한 번에 제거해야 한다.
•
cf) 애그리거트 하위 뎁스가 깊을 경우
◦
정말 정합성이 맞아야한다면 묶어야 됨
◦
도메인 룰이 어떠한지가 중요하지 뎁스가 어떤지가 중요하진 않음
◦
작으면 작을수록 좋은데 그렇다고 무리하게 작게만들필요는 없다