들어가기에 앞서
다른 포스팅에서도 얘기했던 것 처럼 서비스가 성장하면서 가장 많이 고민했던 부분 중 하나가 “복잡해지는 비즈니스 로직/도메인 규칙을 어떻게 잘 관리할것인가” 였다.
지금 재직중인 회사에서 보일러플레이트로 삼고 있는 아키텍처에 대한 강의를 접하게 되어 내용을 학습하게 되었는데 DDD 기반의 아키텍처가 상당히 잘 구성되어있어서 도움이 많이 되었다.
이와 관련하여 내용을 정리해보고자 한다.
1. 프로젝트 구조 및 설계
1.1. 좋은 구현이란?
•
비즈니스 가치를 명확히 충족시켜야 한다.
•
잘 읽혀야 한다.
◦
별도의 문서 없이 코드 자체로 도메인 파악 필요
◦
코드로 표현할 수 없는 외부 요소들은 별도의 기술 문서로 표현
•
테스트 코드 작성이 쉬워야 한다.
◦
코드간의 의존성 높음 → 테스트 코드 작성 어려움
◦
테스트 코드 작성이 쉬움 → 코드 품질 높음
•
변경에 유연해야 한다.
1.2. 도메인 주도 설계
•
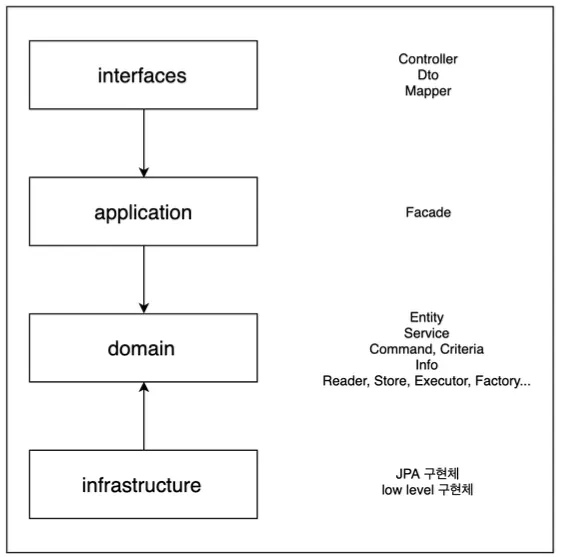
Layer 별 특징과 역할
Layer | Description | Object |
Interfaces | • 사용자에게 정보를 보여주고 사용자의 명령을 해석
• API, GQL Resolver | Controller, DTO, Mapper(Converter) |
application | • 수행할 작업을 정의, 표현력 있는 도메인 객체가 문제를 해결
• 이 계층은 얇게 유지 - 오직 작업을 조정하고 아래 위치한 계층에 포함된 도메인 객체의 협력자에게 작업을 위임 | Facade |
domain | • 업무 개념과 업무 상황에 대한 정보, 업무 규칙을 표현하는 일을 책임
• 업무 상황을 반영하는 상태를 제어하고 사용
• 상태 저장과 같은 관련된 기술적인 세부 사항은 infrastructure 에 위임
• 업무용 소프트웨어의 핵심 | Entity, Service, Command, Criteria, Info, Reader, Store, Executor, Factory (interface) |
infrastructure | • 상위 계층을 지원하는 일반화된 기술적 기능을 제공
• 애플리케이션에 대한 메시지 전송, 도메인 영속화, UI에 위젯 그리기 등 | low level 구현체
(ReaderImpl, StoreImpl, TypeORM, RedisConnector, KafkaProducer) |
•
Layer간 참조 관계
◦
레이어간의 참조관계는 단방향 의존성 유지
◦
계층간의 호출에는 인터페이스를 통한 호출
2. DDD Layer 별 역할 및 구현 상세
2.1. Glossary
[Aggregate]
•
필요성
◦
모델 내에서 복잡한 연관관계를 맺는 객체를 대상으로 일관된 규칙 보장 어려움
◦
개별 객체만이 아닌 서로 밀접한 관계에 있는 객체 집합에도 변경에 대한 일관된 규칙 유지 필요
◦
이를 위해 Aggregate 구성. Aggregate에 적용되는 불변식은 각 트랜잭션이 완료될 때 이행
•
특징
◦
Aggregate는 데이터 변경의 단위로 다루는 연관 객체의 묶음
◦
각 Aggregate에는 루트(Root)와 경계(Boundary)가 있음
▪
경계는 Aggregate에 무엇이 포함되고 포함되지 않는지를 정의
▪
루트는 단 하나만 존재. Aggregate에 포함된 특정 Entity 가리킴
◦
각 루트 Entity는 전역 식별성을 가짐
◦
Aggregate 경계 밖에서는 루트 Entity를 제외한 Aggregate 내부의 구성요소를 참조할 수 없음
•
Aggregate 는 생명주기의 전단계에서 불변식이 유지 되어야할 범위 표시
[Factory & Repository]
•
필요성
◦
복잡한 객체를 생성하는 것은 도메인 계층의 책임이나, 그것이 모델을 표현하는 객체에 속하는 것은 아님
◦
복잡한 객체와 Aggregate의 인스턴스 생성을 책임지는 별도의 객체를 선언하여 운영하는 것이 필요
•
특징
◦
자신의 책임과 역할이 다른 객체를 생성하는 것 = Factory
◦
Factory는 해당 Factory에서 만들어내는 객체와 매우 강하게 결합돼있음 → 자신이 생성하는 객체와 가장가까이 있어야함
◦
Factory는 Aggregate에서 유지되어어야할 불변식 로직을 Factory 내에 두어 Aggregate 내에 들어있는 복잡한 요소를 줄일 수 있음
•
특정 객체나 Aggregate 를 생성하는 일이 복잡해지거나 내부 구조를 너무 많이 드러내는 경우 Factory 사용
2.2. Domain Layer
•
역할
◦
업무 개념과 업무 상황에 대한 정보, 업무 규칙을 표현하는 일을 책임
◦
업무 상황을 반영하는 상태 제어
◦
상태 저장과 관련된 기술적인 세부사항은 인프라 스트럭처에 위임
◦
업무용 소프트웨어의 핵심
•
표준 구현
1.
Domain Layer에서의 Service에서는 해당 도메인의 전체 흐름을 파악할 수 있게 구현되어야 함
2.
Domain Layer에서의 모든 클래스명이 xxxService로 선언될 필요는 없음
•
주요 도메인 흐름을 관리하는 Service는 하나로 유지, 이를 위한 support 역할을 하는 클래스는 Service 이외의 네이밍 사용 권장
•
하나의 책임을 가져가는 각각의 구현체는 그 책임 및 역할에 맞는 네이밍으로 선언
◦
예) xxxReader / xxxStore / xxxExecutor / xxxFactory / xxxAggregator
◦
다만, 해당 구현체는 Domain Layer에서 interface로 추상화하고, 실제 구현체는 Infrastructure layer에서 구현 (DIP 개념)
▪
Domain Layer - Service / ServiceImpl
▪
Infrastructure Layer - ReaderImpl / StoreImpl / ExecutorImpl
3.
Service 간에는 참조 관계를 가지지 않도록 함
•
Service 내의 로직은 추상화 수준을 높게 가져감
•
각 추상화의 실제 구현체를 잘게 쪼갬
2.3. Infrastructure Layer
•
역할
◦
상위 계층을 지원하는 일반화된 기술적 기능 제공
•
표준 구현
◦
Domain Layer에 선언되고 사용되는 추상화된 interface를 실제로 구현
◦
runtime시에는 실제 로직을 동작 (DIP)
◦
Domain의 추상화된 interface를 구현하는 레이어로 구현의 자유도 높음
◦
Infrastructure layer 에서의 구현체간의 참조 관계 허용
▪
domain layer에 선언된 interface를 구현하는게 대부분이므로 service에 비해 의존성을 많이 가지지 않음
▪
로직 재활용을 위해 infrastructure 내 구현체를 의존관계로 활용 해도 됨
▪
단, 순환 참조가 발생하지 않도록 적절한 상하관계 정의 필요
2.4. Application Layer
•
역할
◦
수행할 작업 정의
◦
도메인 객체가 문제를 해결하도록 지시
◦
다른 애플리케이션 계층과의 상호작용 진행
◦
비즈니스 규칙 포함 X. 작업을 조정하며 다음 하위 계층에서 도메인 객체의 협력을 위해 업무 위임 → Layer가 얇음
◦
작업을 조정하기만 하며, 도메인 상태를 가지면 안됨
•
의문점
◦
수행할 작업을 정의하고 작업을 조정하는게 결국 도메인 로직 아닌가?
◦
다른 애플리케이션 계층과 상호작용 → import & 생성자 인자가 많아질 수 밖에 없지 않나??
•
표준 구현
◦
역할
▪
transaction으로 묶어야하는 도메인 로직
▪
그 외 로직을 aggregation하는 역할로 한정
◦
네이밍
▪
xxxFacade로 명명
▪
사전적 개념
•
복잡한 여러 개의 API를 하나의 인터페이스로 aggregation하는 역할
▪
DDD의 개념
•
서비스 간의 조합으로 하나의 요구사항을 처리하는 클래스
2.5. Interface Layer
•
역할
◦
사용자에게 정보를 보여주고 사용자의 명령을 해석하는 책임
•
표준 구현
◦
Req / Res
▪
API를 설계시 없어도 되는 Request parameter 제거
▪
외부에 리턴하는 Response 도 최소한으로 유지
◦
서비스간 통신 기술
▪
http / gRPC, 비동기 메세징과 같은 서비스간 통신 기술은 interface layer에서만 가급적 사용
2.6. Summary
•
Interface Layer
◦
Controller
◦
Input / Output
▪
Request Dto
▪
Response Dto
•
Application Layer
◦
Facade
•
Domain Layer
◦
Service / ServiceImpl
▪
Input / Output
•
Input
◦
Command - CUD
◦
Criteria - R
•
Output
◦
Info - Entity Converted Object
◦
Interface
▪
Reader - R 로직
▪
Store - CUD 로직
▪
Executor
▪
Processor
▪
Generator
▪
Factory
•
Infrastructure Layer
◦
Implementation
▪
ReaderImpl
▪
StoreImpl
▪
ExecutorImpl
▪
ProcessorImpl
▪
GeneratorImpl
◦
Repository
3. 권장 구현 방식
3.1. 개발 디자인 문서
•
개발 디자인 문서를 선행적으로 작성 후 구현
•
개발 전 개발 디자인 문서 작성 후 공유
•
서비스 구현에 필요한 목표, 설계, 제약 사항등을 생각해보고 개발 진행 → 시행착오 최소화
•
개발 디자인 피어 리뷰 → 더 나은 디자인과 방향성 설정 가능
예시
3.2. 핵심 도메인 도출
•
핵심 도메인 도출이 테이블 설계보다 먼저 진행되어야한다.
◦
테이블 - 도메인 객체 영속화를 위한 그릇에 불과
•
우리가 해야할 것
◦
주요 요구사항과 제약조건을 고려
◦
핵심 도메인 객체 도출
◦
특정 기능 수행을 위한 도메인간에 주고 받아야할 메세지 먼저 정의
3.3. 그 외..
•
변수명, 메서드명에 많이 신경 쓰자
◦
표준, 네이밍 규칙 설정 및 운영
•
API 명세 최적화
◦
꼭 필요한 프로퍼티만 넣을 것
•
setter 최대한 지양
◦
캡슐화된 도메인 객체 오염 주범
•
transaction 사용과 범위 설정에 대한 많은 고민 진행할 것
◦
범위가 작으면 작을수록 좋다…
•
도메인 객체가 무조건 DB에 저장되지는 않음
•
try-catch는 필요한 경우가 아니라면 지양하자
◦
exception을 catch 했을 때 추가적인 로직 구현이 필요한 경우에만 선언
◦
try-catch가 필요한 케이스
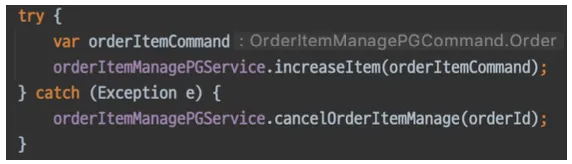
•
꼭 필요한 상태만 선언하자
◦
도메인 객체의 상태값은 식별자 만큼이나 중요한 프로퍼티
◦
다만, 너무 세분화된 상태값은 코드 구현의 난이도와 복잡도를 높임
4. 도메인 개발 예시
4.1. Glossary
•
이해 관계자
◦
유저 - 서비스를 통해 상품을 선택하여 주문하는 고객
◦
파트너 - 해당 서비스에 입점하여 상품을 판매하는 업체
◦
내부 운영자 - 해당 서비스를 운영하고 관리하는 담당자
•
도메인
◦
파트너 - 파트너 등록과 운영을 처리
◦
상품 - 상품과 상품의 옵션 정보를 등록/관리
◦
주문 - 유저가 선택한 상품/주문 정보를 관리 및 결제
•
요구사항
4.2. DDD의 Aggregate
•
예시) 상품 도메인 Entity
◦
Item
◦
ItemOptionGroup
◦
ItemOption
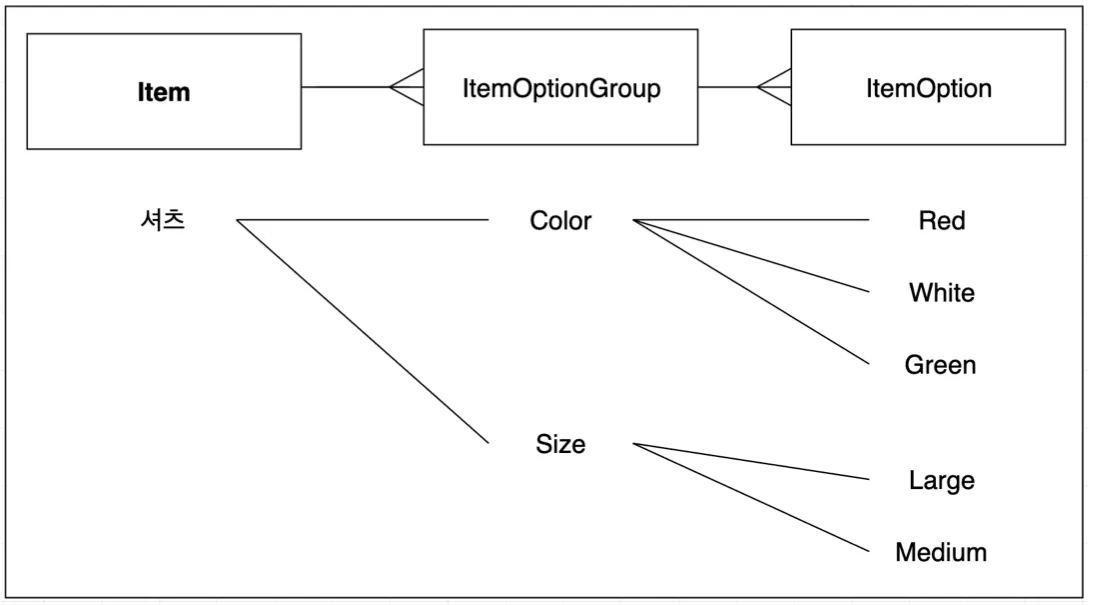
•
Aggregate Root
◦
Item은 Item 도메인 전체의 Aggregate Root 역할
◦
Aggregate Root 경계 밖에서는 Aggregate 내부 구성요소를 참조할 수 없음
◦
Item을 획득하면 Aggregate 내부의 객체를 탐색해서 획득할 수 있게 됨
◦
Item Aggregate 내부에서는 데이터가 변경될때마다 유지되어야하는 일관된 규칙이 지켜져야한다.
◦
일관된 규칙은 Aggregate Root에 적용되는 모든 트랜잭션 내에서 지켜져야한다. → 규칙이 깨지면 트랜잭션 롤백이 발생
•
Factory
◦
복잡한 객체와 Aggregate 인스턴스 생성에 책임
◦
객체를 데이터베이스와 같은 저장소에 영속화 하는것의 역할은 포함하지 않음. 해당 역할은 Repository가 수행
4.3. Service 및 Implements 구현
•
도메인 로직과 Service의 역할
◦
코드를 통해 해당 도메인의 전체 흐름 파악 필요
◦
세세한 구현과 low level 기술은 implements (infrastructure)에 위임, 위임을 맡기는 구간은 interface로 정의해서 사용
◦
Service 간에는 참조 관계 두지 않음
•
PartnerService<I>에서 제공해야할 요구사항
◦
파트너 등록
◦
파트너 정보 조회
◦
파트너 활성화/비활성화
•
Command, Criteria, Info 객체
◦
Command, Criteria
▪
Service 메서드 처리와 조회를 위한 파라미터
•
Command: CUD
•
Criteria: R
◦
Info
▪
리턴 객체
▪
Database에서 조회하여 가져온 Entity를 그대로 리턴 하지 않기 위한 객체
▪
도메인 로직의 리턴값으로 Entity를 그대로 리턴하지 않음
•
도메인 로직의 리턴 값으로 Entity를 그대로 전달하면 domain layer 바깥에서 entity 내의 도메인 로직이 호출되거나 상태가 변경되는 명령어가 실행될 수 있음
→ 도메인 로직을 domain layer에 응집하고자 하는 의도와 맞지 않음
▪
Info 객체는 필요에 따라 Entity의 일부 속성을 가공할 수 있음
•
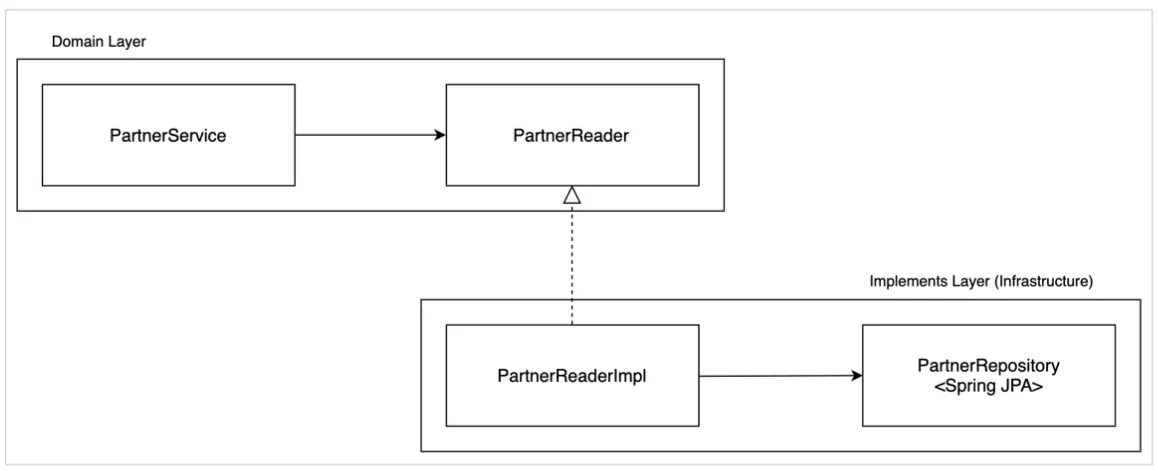
파트너 Entity가 제공하는 기능과 세부적인 기술을 제공하는 Implements 와의 조합으로 PartnerService의 구현체 만듦
◦
Partner 도메인의 조회와 저장을 담당하는 interface 각각 선언
▪
PartnerReader - 조회
▪
PartnerStore - 저장
•
ItemService<I>에서 제공해야할 요구사항
◦
상품 등록
◦
상품 정보 조회
◦
상품 판매 상태 변경 (가능/불가능)
•
상품 등록
◦
Item Aggregate 생성을 위한 Factory 구현
◦
예) 복잡한 객체 생성 로직을 ItemOptionSeriesFactory 에서 구현 → 도메인 서비스에서 적절한 추상화를 통해 가독성 유지
4.4. Application 및 Interfaces 구현
•
Facade (Application layer) 구현
◦
파트너 등록 시, 등록 성공 후 해당 파트너에게 이메일로 등록 성공 알림을 보내는 요구사항
▪
파트너 등록 과정의 모든 도메인 로직을 하나의 transaction으로 묶어야 정합성 이슈 없음
▪
이메일 발송의 경우 발송에 실패하더라도 파트너 등록에 정상적으로 이루어졌다면 큰 문제가 안됨
(요구사항에 대한 판단과 해석은 관련 팀과 협의하면서 진행)
◦
응용 계층을 하나 더 둠으로써 도메인 계층에서 처리하기 애매한 요구사항 충족할 수 있는 여유가 생김
▪
필요에 따라 여러 개의 Info를 조합하여 만드는 Result 객체 필요할 수 있음
▪
이때 여러개의 Service를 호출하여 이를 조합하는 Result 생성 로직 생길 수 있음
•
Controller (Interfaces) 구현
◦
사용자에게 정보를 보여주고 사용자에게 명령을 해석하는 책임
◦
서비스 전체의 시스템간의 인터페이스 표준 정의, 그에 맞게 외부 호출과 응답 정의되도록 구현
◦
외부 서비스의 요청과 응답은 내부 도메인 로직을 처리하는 layer와 명확히 분리되어야 한다
▪
interface layer에서 사용할 dto를 정의하고 dto가 domain layer로 침투되지 않게 유의
▪
이를 위한 convert 로직 필요
•
request dto → domain의 command/criteria
•
domain info → response dto
•
변환 로직을 dto 내에 구현하는 것은 응집도를 높일 수 있음
◦
인터페이스 계층에서만 사용할 dto를 정의
▪
static class 적극 활용
▪
validation 정의
◦
Facade를 호출하고 결과를 받아 API 응답에 맞게 변환