

내용 정리
1. B 트리
1.1. 정의
•
보편적인 색인 구조
•
전통적으로 4KB 크기(때로는 더 큰)의 고정 크기 블록 또는 페이지로 나눔
한번에 하나의 페이지에 읽기 또는 쓰기를 진행
•
디스크가 고정 크기 블록으로 배열되기 때문에, 근본적으로 하드웨어와 더 밀접한 관련이 있음
•
각 페이지는 주소나 위치를 이용해 식별 가능
◦
이 방식으로 하나의 페이지가 다른 페이지 참조 가능
◦
포인트와 비슷한 개념이나 메모리가 아닌 디스크에 존재
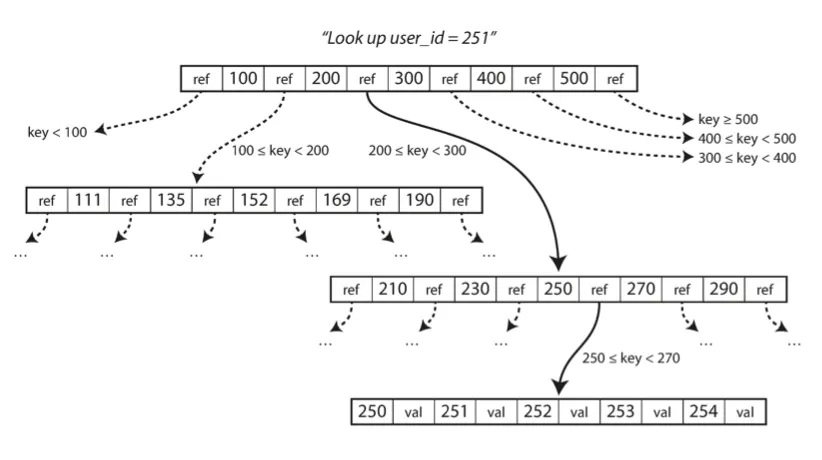
1.2. 특징
•
정렬된 키-값 쌍으로 유지 → 키-값 검색 및 범위 질의에 효율적
•
관계형 데이터 베이스의 표준 색인 구현 (비관계형 데이터베이스에서도 많이 활용)
•
탐색 방식 (색인)
◦
한 페이지는 B 트리의 루트(root)로 지정
▪
색인에서 키를 찾으려면 루트에서 시작
◦
페이지는 여러 키와 하위 페이지의 참조를 포함
◦
각 하위페이지에 저장된 키가 계속 이어지는 범위를 담당
▪
참조 사이의 키는 해당 범위의 경계가 어디인지 나타냄
◦
최종적으로 개별 키(리프 페이지; leaf page) 를 포함하는 페이지에 도달
▪
이 페이지는 각 키의 값을 포함 하거나 값을 찾을 수있는 페이지의 참조를 포함
•
분기 계수
◦
B 트리의 한 페이지에서 하위 페이지를 참조하는 수
•
값 갱신 및 추가
◦
갱신
▪
키를 포함하고 있는 리프 페이지 검색 후 페이지의 값을 바꾼 다음, 페이지를 디스크에 기록
▪
페이지에 대한 모든 참조는 계속 유효함
◦
추가
▪
새로운 키를 포함하는 범위의 페이지를 찾아 해당 페이지에 키와 값을 추가
◦
새로운 키를 수용한 페이지에 여유 공간이 없는 경우
▪
페이지를 반으로 나눔
▪
상위 페이지가 새로운 키 범위의 하위 부분을 알 수 있게 갱신
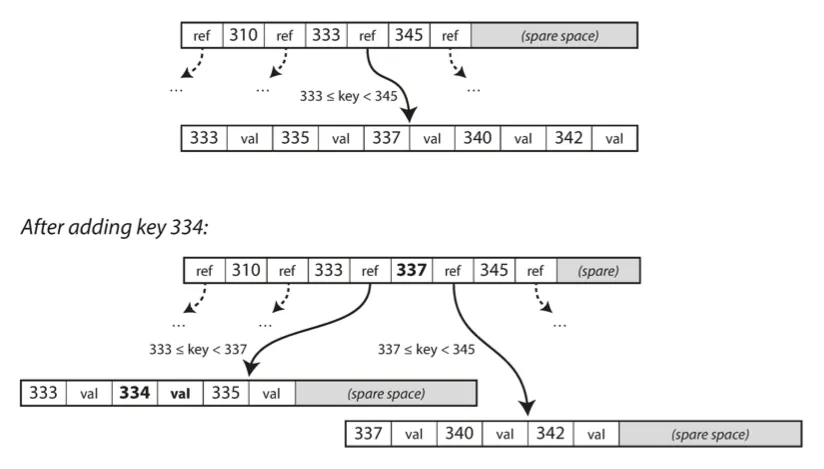
▪
위 알고리즘은 트리가 계속 균형을 유지하는 것을 보장함
1.3. 시간복잡도
•
N개의 키를 가진 B 트리의 깊이는 항상 O(logN)이다.
•
대부분의 데이터베이스는 B 트리의 깊이가 3~4단계에서 충분히 검색 가능
•
분기 계수 500의 4KB 페이지의 4단계 트리는 256TB의 3승까지 저장 가능
1.4. 신뢰할 수 있는 B트리 만들기
•
쓰기 동작
◦
새로운 데이터를 디스크 상의 페이지에 덮어씀
◦
덮어쓰더라도 페이지를 가리키는 모든 참조는 온전히 남음
◦
cf)
▪
로그 구조화 색인은 파일에 추가함. 같은 위치의 파일은 변경하지 않음
•
쓰기 전 로그 (Write-ahead log, WAL; 재실행 로그)
◦
여러 페이지를 덮어 써야 하는 경우, 일부만 기록되고 DB가 고장난다면 고아 페이지가 발생할 수 있음
◦
데이터베이스 고장상황에서 스스로 복구할 수있게 만들기위해 디스크 상에 WAL이라고 하는 데이터 구조를 추가해 B 트리를 구현
◦
트리 페이지에 변경된 내용을 적용하기전에 모든 B 트리의 변경사항을 기록하는 추가 전용 파일
◦
데이터 베이스 고장 이후 복구될 때 일관성 있는 상태로 B 트리를 다시 복원하는데 사용
•
동시성 제어
◦
다중 스레드가 동시에 B 트리에 접근하는 경우
◦
래치(latch): 가벼운 잠금으로 트리의 데이터 구조를 보호
1.5. B 트리 최적화
•
쓰기시 복사 방식 (Copy-on-write schema)
◦
페이지 덮어 쓰기와 고장 복구를 위한 WAL 유지 대신 일부 데이터베이스에서 사용
◦
변경된 페이지는 다른 위치에 기록
◦
트리에 상위 페이지의 새로운 버전을 만들어 새로운 위치를 가리키게 함
◦
동시성 제어에도 유용
•
페이지에 키를 축약하여 공간 절약
•
리프 페이지를 디스크 상에 연속된 순서로 나타나게끔 트리 배치
•
트리에 포인터 추가
◦
리프 페이지 양쪽에 형제 페이지에 대한 참조를 가지면 순서대로 키 스캔 가능
▪
B+트리
•
프랙탈 트리
1.6. B트리 vs LSM 트리
•
LSM 트리 장점
◦
B 트리 색인은 모든 데이터 조각을 최소한 두번 기록 해야 함
▪
쓰기전 로그 & 트리 페이지
◦
로그 구조화 색인
▪
SS 테이블의 반복된 컴팩션과 병합으로 인해 여러번 데이터를 써야함
▪
쓰기 증폭 (write amplification)
•
데이터베이스 쓰기 한번이 데이터베이스 수명 동안 디스크에 여러번 쓰기를 야기하는 효과
◦
쓰기증폭이란, 1번의 데이터 베이스 쓰기가 1번이 아닌 여러번 쓰기를 유발하는 현상을 일컫음
•
SSD는 수명이 다할때까지 블록 덮어쓰기 횟수가 제한되므로 쓰기 증폭이 SSD에 유용함
•
쓰기가 많은 애플리케이션의 성능 병목 - 디스크 쓰기 속도
◦
쓰기 증폭 = 성능 비용
◦
LSM 트리는 B 트리보다 쓰기 처리량을 높게 유지할 수 있음
▪
순차적으로 컴팩션된 SS테이블 파일을 쓰기 때문
◦
압축률이 좋음
▪
저장소 오버헤드가 낮음
▪
페이지 지향적이지 않고, 주기적으로 파편화를 없애기위해 SS 테이블을 다시 기록함
◦
SSD
▪
SSD 펌웨어는 저장소 순차적 쓰기 패턴을 위해 내부적으로 로그 구조화 알고리즘을 사용
▪
낮은 쓰기 증폭과 파편화 감소는 SSD에 유리
•
LSM 트리 단점
◦
컴팩션 과정이 때로는 진행중인 읽기/쓰기에 영향을 줄 수 있음
▪
컴팩션을 점진적으로 백그라운드에서 수행
▪
그러나 디스크가 가진 자원은 한계가 있음
▪
비싼 컴팩션 연산이 끝날때 까지 요청이 대기해야하는 상황이 발생할 수 있음
◦
높은 쓰기 처리량
▪
디스크 쓰기 대역폭은 유한함, 일부 로직이 대역폭을 공유해야함
•
초기 쓰기(logging)
•
멤테이블을 디스크로 방출(flush)
•
컴팩션 스레드
▪
데이터베이스가 커질수록 컴팩션을 위한 디스크 대역폭이 필요함
◦
컴팩션 주의 깊게 설정 필요
▪
컴팩션이 유입 쓰기 속도를 따라갈 수 없는 경우 발생
▪
디스크상에 병합되지 않은 세그먼트 수는 디스크 공간이 부족할 때까지 증가
▪
더 많은 세그먼트 파일을 확인해야하므로 읽기 또한 느려짐
▪
상황 감지를 위한 명시적 모니터링 필요
•
B 트리 장점
◦
각 키가 색인의 한곳에만 정확히 존재
▪
cf) 로그 구조화 저장소엔진은 다른 세그먼트에 같은 키 다중 복사본 존재 가능
◦
강력한 트랜잭션 시맨틱을 제공하는 데이터베이스에 유리
2. 기타 색인 구조
•
지금까지 살펴본 색인은 키-값 색인
•
관계형 모델의 기본키 색인 (primary key)
◦
관계형 테이블에서 하나의 로우, 문서 데이터베이스에서는 하나의 문서를, 그래프 모델에서는 하나의 정점을 고유하게 식별 가능
•
보조 색인 (secondary index)
◦
키-값 색인에서 쉽게 생성가능
◦
기본키 색인과 다르게 키가 고유하지 않음
◦
같은 키를 가진 많은 로우(문서, 정점)이 존재 가능
▪
해결 방법
•
색인의 각 값에 일치하는 로우 식별자 목록 생성하는 방법
•
로우 식별자를 추가하여 각 키를 고유하게 만드는 방법
2.1. 색인 안에 값 저장하기
•
색인
◦
키: 질의가 검색하는 대상
◦
값
1.
실제 로우(문서, 정점) - 클러스터드 색인
2.
다른곳에 저장된 로우를 가리키는 참조 - 비클러스터드 색인
•
로우가 저장된 곳을 힙파일이라고 함
•
힙파일
◦
특정 순서 없이 데이터 저장
◦
힙 파일 접근 방식이 일반적인 방식
◦
여러 보조 색인이 존재할 경우 데이터 중복 피할 수 있음
◦
키를 변경하지 않고 값을 갱신할 때 효율적
▪
기존의 값 공간을 그대로 사용할 수 있는 경우 → 레코드를 제자리에 덮어씀
▪
기존의 값 공간을 그대로 사용할 수 없는 경우
•
충분한 공간이 있는 새로운 곳으로 위치 이동 필요
•
모든 색인이 레코드의 새로운 힙 위치를 가리키게 갱신 필요
또는, 이전 힙 위치에 전방향 포인터 생성
•
클러스터드 색인 (clustered index)
◦
색인 → 힙파일 이동은 읽기 성능 저하
◦
색인 안에 색인된 로우를 바로 저장
◦
예) InnoDB 저장소 엔진의 테이블 기본키
•
커버링 색인 (covering index) / 포괄열이 있는 색인 (index with included column)
◦
클러스터드 색인과 비클러스터드 색인의 사이 절충안
◦
색인 안에 테이블의 칼럼 일부를 저장
2.2. 다중 컬럼 색인
•
결합 색인 (concatenated index)
◦
하나의 컬럼에 다른 컬럼을 추가하는 방식
◦
하나의 키에 여러 필드를 단순히 결합
•
다차원 색인은 한번에 여러 컬럼에 질의하는 일반적인 방법
◦
표준 B 트리나 LSM 트리 색인은 다차원 색인에 효율적이지 않음
SELECT * FROM restaurants WHERE lat > 51.49 AND lat < 51.5079
AND lon > -0.1162 AND lon < -0.1004;
SQL
복사
◦
전문 공간 색인(specialized spatial index) 를 사용하는 해결 가능
▪
R 트리
2.3. 전문 검색과 퍼지 색인
•
유사한 키에 대한 검색은 기존까지 설명한 색인으로 검색 불가
•
애매모호한 (fuzz) 질의에는 다른 기술 필요
•
예) 전문 검색 엔진
◦
특정 단어 검색 시, 해당 단어의 동의어로 질의 확장
•
루씬의 인메모리 색인
◦
용어 사전을 위해 SS 테이블 같은 구조를 사용
◦
여러 키 내 문자에 대한 유한 상태 오토마톤으로 트라이와 유사
◦
레벤슈타인 오토마톤
▪
특정 편집 거리 내 효율적인 단어 검색 제공
2.4. 모든 것을 메모리 보관
•
개요
◦
지금까지의 모든 색인 및 데이터 구조는 디스크 한계에 대한 해결책임
◦
디스크 / SSD는 메인 메모리에 비교해 다루기 어려움
▪
디스크의 지속성, 램보다 기가바이트당 가격이 저렴한 이유로 디스크 활용
◦
램 가격이 저렴해지면서 인메모리 데이터베이스 개발
•
지속성
◦
디스크에 변경사항의 로그 기록 / 디스크에 주기적으로 스냅샷 기록
◦
인메모리 DB가 재시작 되는 경우, 디스크나 네트워크를 통해 복제본에서 상태를 다시 적재
◦
디스크에 기록하더라도, 읽기는 전적으로 메모리에서 제공됨
•
안티 캐싱 접근 방식
◦
메모리가 충분하지 않을 때, 가장 최근에 사용하지 않은 데이터를 메모리에서 디스크로 보냄
◦
나중에 다시 접근할 때 메모리에 적재
3. 트랜잭션 처리와 분석
3.1. 고수준에서의 저장소 엔진의 분류
1.
트랜잭션 처리 최적화 (OLTP: Online Transaction Processing)
•
최종 사용자가 사용하므로 대량의 요청을 받을 수 있음
•
부하 처리를 위해 애플리케이션은 보통 각 질의마다 작은 수의 레코드만 다룸
•
애플리케이션은 키의 일부만 사용하는 레코드를 요청
•
저장소 엔진은 요청한 키의 데이터를 찾기 위해 색인을 사용
•
디스크 탐색이 병목
2.
분석 최적화(OLAP: Online Analytic Processing)
•
비즈니스 분석가가 주로 사용
•
훨씬 더 적은 수의 질의를 다루나 각 질의는 매우 다루기 어려움
•
짧은 시간에 수백만 개의 레코드를 스캔해야함
•
일반적으로 디스크 대역폭이 병목
•
칼럼 지향저장소는 작업 부하 처리할때 사용가능한 솔루션
3.2 데이터 웨어하우스
•
OLTP 작업에 영향을 주지 않고 분석가들일 마음껏 질의 할 수 있는 개별 데이터베이스
•
OLTP 시스템에 있는 데이터의 읽기 전용 복사본
•
ETL - 데이터 웨어하우스로 데이터를 가져오는 과정
◦
Extract - OLTP 데이터베이스에서 주기적인 데이터 덤프나 지속적인 갱신 스트림을 사용하여 추출
◦
Transform - 분석 친화적인 스키마로 변환
◦
Load - 깨끗하게 정리한 다음 데이터 웨어하우스에 적재
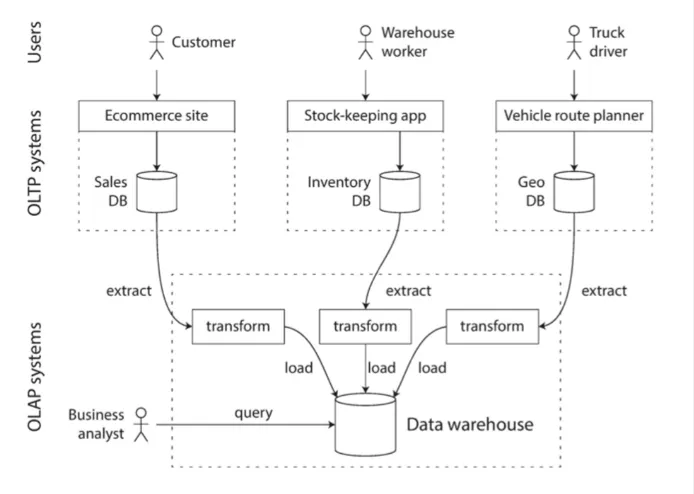
•
OLTP 데이터베이스 vs 데이터 웨어하우스
◦
데이터 웨어하우스의 데이터 모델: 관계형 모델
▪
SQL이 일반적으로 분석 질의에 적합
◦
SQL 질의 생성 후 결과를 시각화하고 데이터 탐색을 도와주는 그래픽 데이터 분석 도구 존재
▪
드릴 다운 (drill-down)
▪
슬라이싱 (slicing)
▪
다이싱(dicing)
◦
표면적으로는 둘다, SQL 질의 인터페이스를 지원하므로 비슷해보임
◦
그러나, 각각 매우 다른 질의 패턴에 맞게 최적화 됐기 때문에 시스템 내부는 다름
3.3. 분석용 스키마: 별 모양 스키마 & 눈꽃송이 모양 스키마
•
별모양 스키마(star schema)
◦
사실 테이블 (fact table)
▪
스키마의 중심에는 이 존재
▪
사실 테이블의 각 로우는 특정 시간에 발생한 이벤트를 의미함
▪
개별 이벤트를 담음
•
분석의 유연성을 극대화 가능
•
다만, 사실 테이블이 매우 커질 수도 있음
◦
차원 테이블 (dimemnsion table)
▪
사실 테이블의 다른 칼럼들이 가리키는 다른 테이블 (외래키 참조)
▪
이벤트의 속성인 누가(who), 언제(when), 어디서(where), 무엇을(what), 어떻게(how), 왜(why)를 나타냄
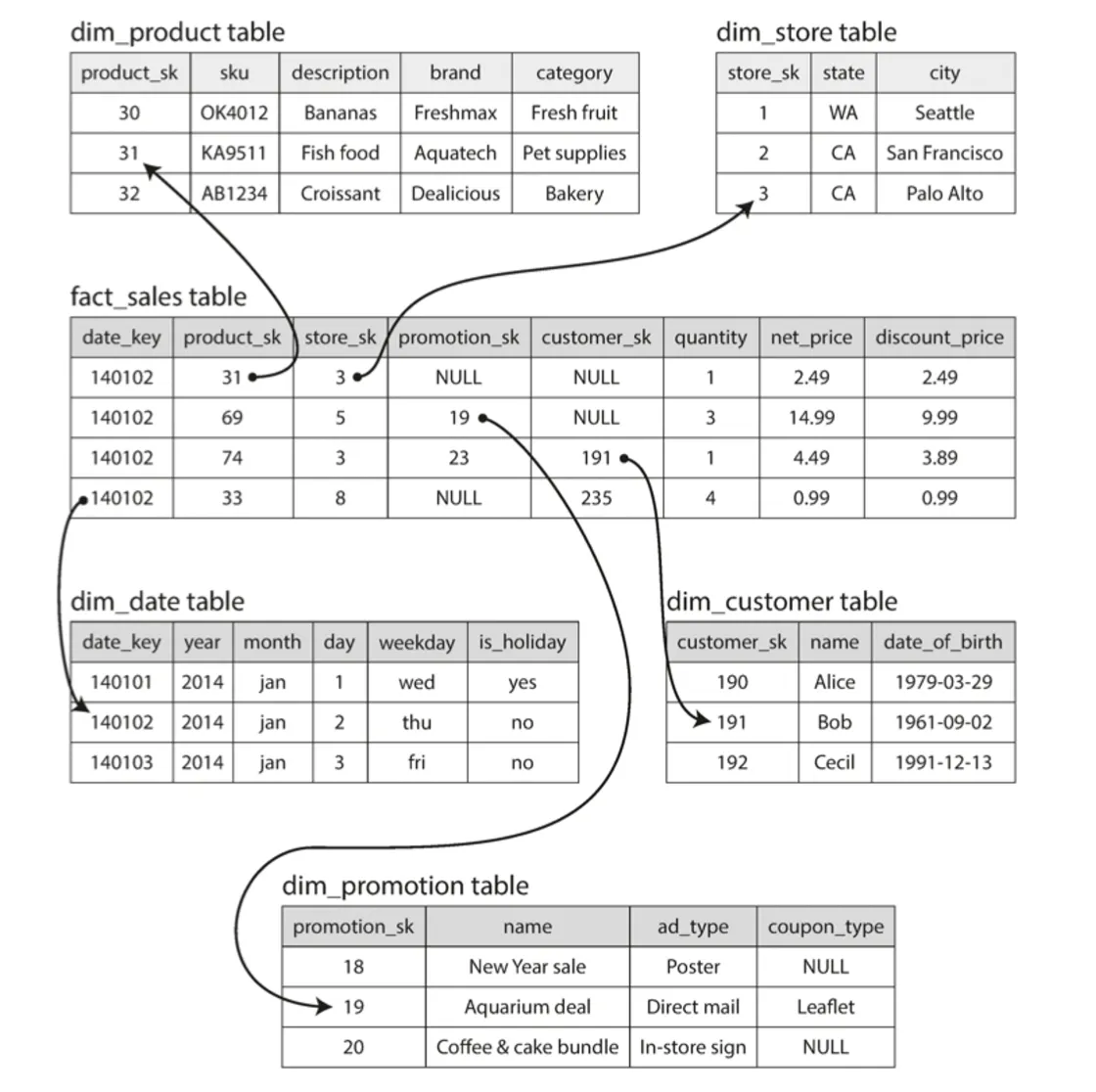
•
눈꽃송이 모양 스키마 (snowflake schema)
◦
별 모양 스키마를 발전 시킨 것
◦
차원을 하위차원으로 더 세분화 한 것
4. 칼럼 지향 저장소
•
데이터 웨어하우스 질의는 일반적으로 한번에 4~5개의 컬럼에만 접근
•
로우의 모든 컬럼의 데이터가 분석용으로 필요하지 않음
•
대부분의 OLTP 데이터베이스에서 저장소는 로우 지향 방식의 데이터를 배치함
•
예시)

◦
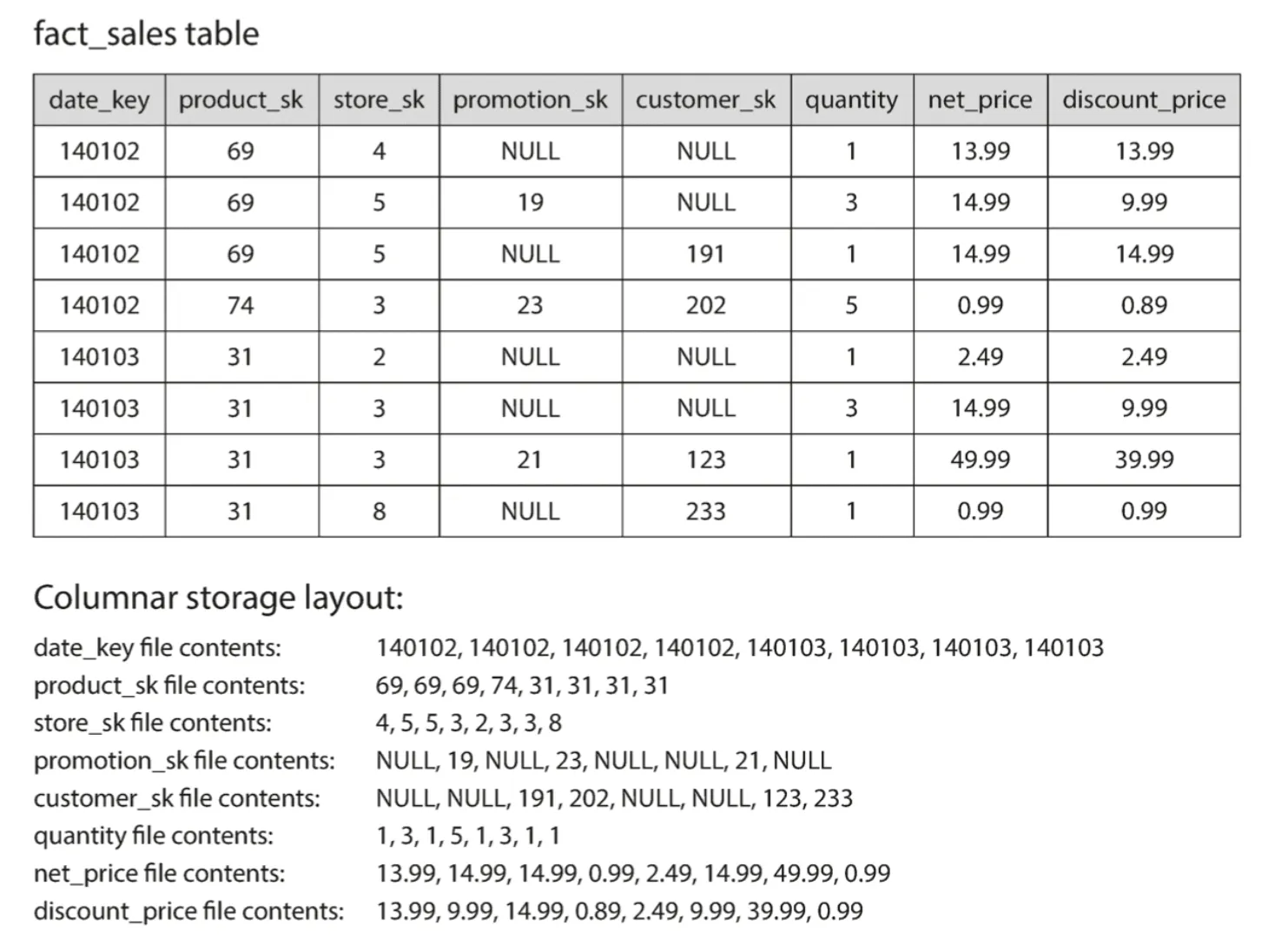
fact_sales.date_key, fact_sales.product_sk 컬럼 모두 혹은 둘중 하나에 색인이 있다고 가정할 경우, 로우 지향 저장소 엔진에서는 모든 로우를 메모리로 적재 한 후, 필요한 후 조건을 충족시키는 로우만 필터링을 해야 한다.
4.1. 정의
•
모든 값을 하나의 로우에 함께 저장하지 않는 대신 각 칼럼별로 모든 값을 저장
•
각 칼럼을 개별 파일에 저장하여 질의에 사용되는 칼럼만 읽고 구분 분석 진행
◦
작업량 대폭 감소 가능
•
컬럼 지향 저장소 배치는 각 칼럼 파일에 포함된 로우가 모두 같은 순서임
•
로우의 전체 값을 다시 모우려면 개별 칼럼 파일의 동일한 인덱스에 위치한 데이터를 모아 구성 가능
•
예시
4.2. 칼럼 압축
•
데이터 압축을 통해 디스크 처리량 감소
•
칼럼 지향 저장소는 압축에 적합함
•
비트맵 부호화
◦
보통 컬럼의 고유 값 수는 로우수에 비해 적음
◦
N개의 고유값을 가진 컬럼을 가져와 N개의 개별 비트맵으로 변환

•
벡터화 처리
4.3. 칼럼 저장소의 순서 정렬
•
칼럼 저장소에서 로우가 저장되는 순서가 반드시 중요하지는 않음
•
삽입된 순서로 저장하는 방식이 가장 쉬움
•
SS 테이블처럼 순서를 도입해 색인 매커니즘으로 사용할 수 있음
•
각 칼럼별로 독립적으로 정렬할 수 없음 → 데이터를 한번에 전체 로우를 정렬해야 함
•
정렬된 순서는 칼럼 압축에 도움이 됨
◦
정렬후 기본 정렬 칼럼은 연속해서 같은 값이 길게 반복됨
◦
런 렝스 부호화 등으로 칼럼 압축 가능
◦
첫번째 정렬키에서 가장 강력함
◦
두번째 또는 세번째 정렬 키는 그보다 뒤섞여 있어 반복 값이 그렇게 길지 않음
4.4. 칼럼 지향 저장소의 쓰기
•
칼럼 지향 저장소, 압축, 정렬은 모두 읽기 질의에 최적화 되어있음
•
따라서 쓰기를 어렵게 한다는 단점이 있음
•
B 트리 사용과 같은 제자리 갱신(update-in-place) 접근 방식은 압축된 컬럼에서 불가능
◦
정렬된 테이블 중간에 로우를 삽입하는 경우, 모든 칼럼 파일을 재작성 해야함
•
LSM 트리 활용 가능
4.5. 집계: 데이터 큐브와 구체화 뷰
•
구체화 집계 (materialized aggregate)
◦
count, sum, avg, min, max 등 집계 함수
•
구체화 뷰 (materizalized view)
◦
질의가 자주 사용되는 집계 함수의 결과 값을 캐싱
◦
디스크에 기록된 질의 결과의 실제 복사본
◦
원본 데이터를 변경하면 구체화 뷰를 갱신해야 함
▪
구체화 뷰는 원본 데이터의 비정규화된 복사본이기 때문
▪
데이터베이스가 이 작업을 자동으로 수행 가능
▪
그러나, 갱신으로 인한 쓰기는 비용이 비싸므로 OLTP 데이터베이스에서 구체화 뷰는 자주 사용되지 않음
▪
데이터 웨어하우스는 읽기 비중이 크므로 구체화 뷰 사용 전략은 합리적일 수있음
◦
표준 뷰 (= 구체화 뷰)
▪
테이블 같은 객체로 일부 질의 의 결과가 내용임
◦
가상 뷰 (=일반적으로 생각하는 뷰)
▪
질의를 작성하는 단축 키
•
말 그대로 쿼리 단축키
▪
SQL 엔진은 뷰의 원래 질의로 즉석에서 확장하고 나서 질의를 처리
•
데이터 큐브 (data cube, OLAP 큐브)
◦
일반화된 구체화 뷰의 특별 사례임. 다양한 차원으로 그룹화한 집계 테이블
◦
특정 질의를 효과적으로 미리 계산 했기 때문에 해당 질의를 수행할 때 매우 빠름
스터디
Harry
쓰기 증폭이란?
색인의 값이 저장되는 방식 2가지를 비교하여 설명하시오
OLTP와 OLAP의 특징을 비교하시오
구체화 뷰를 OLTP에서 잘 쓰이지 않는 이유는?
Matthew
B 트리 구조의 설계 철학과 LSM 트리 구조 설계 철학의 차이점은?
B 트리에서 데이터 베이스 고장 상황에 대비하기 위해 무엇을 하는가?
안티캐싱 접근 방식이란?
(optional) 색인 알고리즘이 OLTP 에서 잘 동작하지만 분석 질의의 응답에선 별로 좋지 않은 이유는?