

List
Search







Preface
•
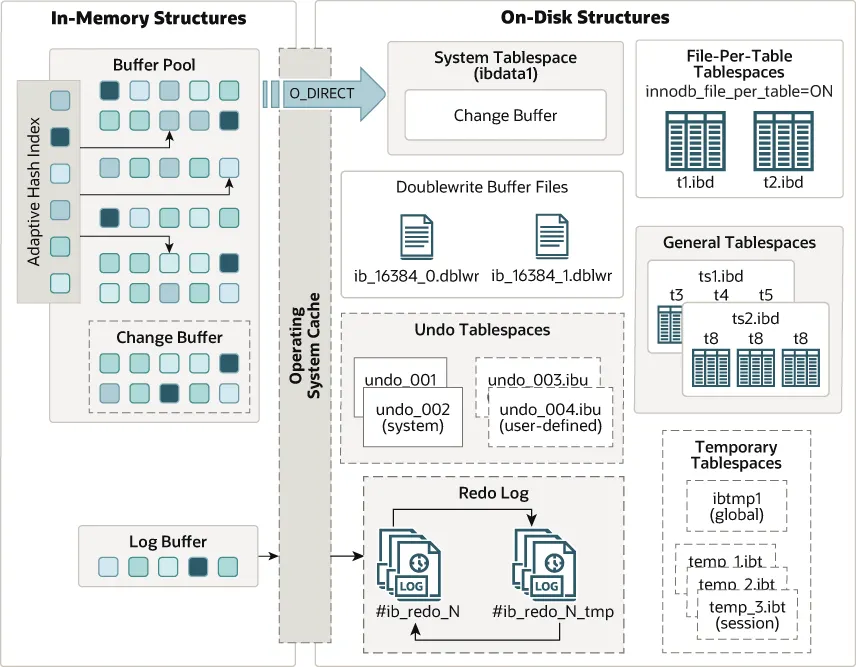
InnoDB 스토리지 엔진 아키텍처 구성
◦
인메모리 스트럭처
▪
버퍼 풀
▪
체인지 버퍼
▪
어댑티브 해시 인덱스
▪
(리두) 로그 버퍼
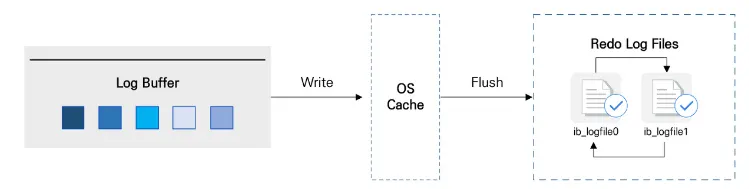
1. 로그 버퍼 (리두 로그 버퍼)
1.1. 정의
•
디스크의 로그 파일에 기록될 데이터를 보유하는 메모리 영역
•
로그 버퍼의 내용은 주기적으로 디스크에 플러시됨
•
로그 버퍼의 크기
◦
innodb_log_buffer_size 변수로 정의
◦
기본 크기는 64MB
1.2. 특징
•
데이터 변경 내용을 로그로 먼저 기록
◦
리두 로그를 WAL (Write Ahead Log) 라고도 부름
•
대부분의 DBMS는 읽기 성능을 고려한 자료구조이므로, 파일 쓰기는 디스크 랜덤 액세스가 필요
•
변경된 데이터를 데이터 파일에 기록하려면 상대적으로 큰 비용이 필요 → 성능 저하
•
리두 로그는 쓰기 비용이 낮은 자료구조를 갖고 있으므로 일반적으로 순차적으로 기록되어 랜덤 액세스 X
•
디스크 기록 및 플러시 방식 제어
◦
innodb_flush_log_at_trx_commit
2. 어댑티브 해시 인덱스
2.1. 정의
•
InnoDB 스토리지 엔진에서 사용자가 자주 요청하는 데이터에 대해 자동으로 생성하는 인덱스
◦
버퍼 풀 공간의 일정 부분 (1/64)을 Adaptive Hash Index 라는 공간으로 사용
•
innodb_adaptive_hash_index 시스템 변수를 통해 기능 활성화/비활성화 가능
•
B-Tree 검색 시간을 줄여주기 위해 도입된 기능
◦
자주 읽히는 데이터 페이지의 키 값을 이용해 해시 인덱스를 만듦
◦
해당 인덱스를 검색하여 레코드가 저장된 데이터 페이지 접근 가능
◦
B-Treee를 루트 노트 → 리프 노드까지 찾아가는 비용 X
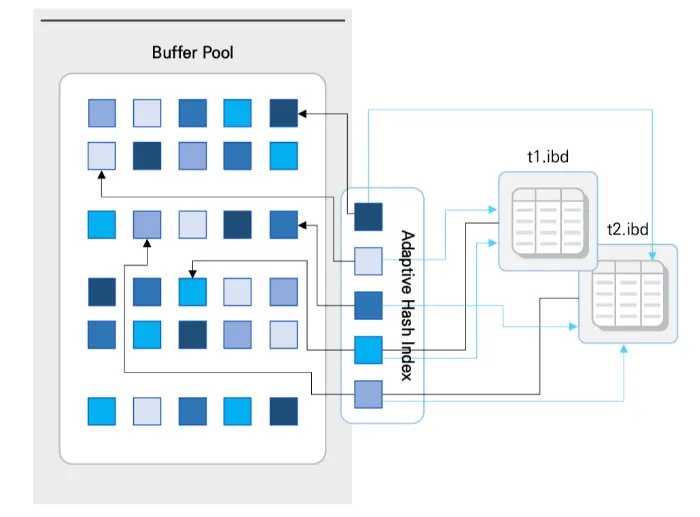
•
해시 인덱스의 구성
◦
인덱스 키 값
▪
B-Tree 인덱스 고유번호(Id) && B-Tree 인덱스 실제 키 값 조합
◦
데이터 페이지 주소
•
매커니즘
◦
해시 인덱스 조회 → 존재하는 경우 → 즉시 해당 데이터 페이지로 연결
•
어댑티브 해시 인덱스 파티션
◦
이전 버전에는 하나의 메모리 객체로 인해 경합 자주 발생
◦
MySQL 8.0 부터는 파티션 기능 제공
▪
innodb_adaptive_hash_index_parts
▪
기본값: 8개
2.2. 예시
•
테이블과 인덱스 생성 & 데이터 삽입
CREATE TABLE employees (
employee_id INT PRIMARY KEY,
first_name VARCHAR(50),
last_name VARCHAR(50),
department_id INT
);
CREATE INDEX idx_department ON employees(department_id);
INSERT INTO employees VALUES (1, 'John', 'Doe', 10);
INSERT INTO employees VALUES (2, 'Jane', 'Smith', 20);
INSERT INTO employees VALUES (3, 'Alice', 'Johnson', 10);
INSERT INTO employees VALUES (4, 'Bob', 'Brown', 30);
SQL
복사
•
B-Tree 인덱스
◦
idx_department 인덱스는 B-Tree 구조로 저장됨
▪
인덱스의 키 값은 department_id
▪
예를 들어, department_id = 10인 두 직원(John Doe와 Alice Johnson)이 있다면, B-Tree 인덱스는 이들을 10이라는 키 값으로 연결함
◦
각 키 값은 해당하는 데이터 페이지 주소를 가리킴
▪
예를 들어, 10이라는 키 값은 직원 ID 1과 3이 저장된 데이터 페이지를 가리킬 수 있음
•
해시 인덱스 생성
◦
InnoDB의 어댑티브 해시 인덱스가 자동으로 활성화되어 있고, 이 인덱스를 사용하기로 가정
◦
해시 인덱스
▪
idx_department B-Tree 인덱스의 일부로 만들어짐
▪
키 값: idx_department의 고유번호(ID)와 department_id 값이 결합되어 생성
◦
예시)
▪
idx_department의 고유번호가 ID123이라고 가정하고,
▪
department_id 값이 10인 경우, 해시 인덱스 키는 ID123-10이 됩니다.
▪
이 키 값은 해당 department_id 값에 해당하는 데이터 페이지의 주소를 가리키는 해시 테이블에 저장됨
•
해시 인덱스를 이용한 검색
(누군가가 department_id = 10인 모든 직원을 검색하려고 할 때)
◦
InnoDB는 먼저 해시 인덱스를 조회
◦
해시 인덱스에서 ID123-10이라는 키 값을 찾음 → 즉시 해당 데이터 페이지로 연결됩니다.
◦
따라서 InnoDB는 10에 해당하는 데이터 페이지로 곧바로 이동
◦
John Doe와 Alice Johnson의 데이터를 빠르게 읽음
2.3. 특징
•
어떤 경우에 사용해야하나?
◦
어댑티스 해시 인덱스가 도움이 되지 않는 경우
▪
디스크 읽기가 많은 경우 / 매우 큰 데이터를 가진 테이블의 레코드를 폭넓게 읽는 경우
•
정렬된 B-Tree 인덱스가 더 효율적
▪
특정 때턴의 쿼리가 많은 경위조인이나 LIKE 패턴 검색)
•
조인 쿼리 → 다양한 테이블 간 맵핑 필요하므로 복잡함. B-Tree 계층 구조가 오히려 유리
•
Like 패턴 → 특정 키 값으로 검색 어려움
◦
어댑티브 해시 인덱스가 도움이 되는 경우
▪
디스크의 데이터가 InnoDB 버퍼 풀 크기와 비슷한 경우{디스크 읽기가 많지 않은 경우)
▪
동등 조건 검색(동등 비교와 IN 연산자)이 많은 경우
▪
쿼리가 데이터 중에서 일부 데이터에만 집중되는 경우
•
양날의 검
◦
저장 공간인 메모리를 사용하므로, 생성/제거 등이 필요
◦
InnoDB 엔진이 항상 해시 인덱스에 접근하여 키 값 존재 유무 확인
◦
데이터 삭제 작업에도 많은 영향 (해시 인덱스도 함께 제거해야하므로)
•
어댑티브 해시 인덱스 효율
◦
해시 인덱스 히트율 / 해시 인덱스 사용 메모리 공간 / 서버 CPU 사용량 종합 판단 필요
▪
헤시 인덱스 히트율: 어댑티브 해시 인덱스 사용 횟수 전체 검색 횟수
•
아래 예시) (1.03 / 3.67) * 100 = 28%
INSERT BUFFER AND ADAPTIVE HASH INDEX
-------------------------------------
Hash table size 8747, node heap has 1 buffer(s)
Hash table size 8747, node heap has 0 buffer(s)
Hash table size 8747, node heap has 0 buffer(s)
Hash table size 8747, node heap has 0 buffer(s)
Hash table size 8747, node heap has 0 buffer(s)
Hash table size 8747, node heap has 0 buffer(s)
Hash table size 8747, node heap has 0 buffer(s)
Hash table size 8747, node heap has 0 buffer(s)
1.03 hash searches/s, 2.64 non-hash searches/s
SQL
복사
◦
어댑티브 해시 인덱스의 메모리 사용량을 조회확인하여 비활성화 여부 판단
SELECT EVENT_NAME, CURRENT_NUMBER_OF_BYTES_USED
FROM performance_schema.memory_summary_global_by_event_name
WHERE EVENT_NAME='memory/innodb/adaptive hash index';
+-----------------------------------+------------------------------+
| EVENT_NAME | CURRENT_NUMBER_OF_BYTES_USED |
+-----------------------------------+------------------------------+
| memory/innodb/adaptive hash index | 1512 |
+-----------------------------------+------------------------------+
SQL
복사
3. 체인지 버퍼
3.1. 정의
•
버퍼 풀에 없는 보조 인덱스 페이지에 대한 변경 사항을 캐시하는 특별한 데이터 구조
◦
레코드가 INSERT / UPDATE 될때 파일 변경 뿐 아니라 인덱스 업데이트도 필요
◦
인덱스가 많은 경우 상당히 많은 자원을 소모함
◦
버퍼풀에 없는 인덱스를 업데이트해야하는 경우, 즉시 실행하지 않고 임시 공간에 저장
◦
이후 사용자에게 결과를 반환하여 성능 향상
◦
이때 사용하는 임시 메모리 공간을 체인지 버퍼라고 함
3.2. 체인지 버퍼링 구성
•
체인지 버퍼의 매커니즘
◦
테이블에서 INSERT, UPDATE, DELETE 작업이 수행될 때, 인덱싱된 열(특히 보조 키 값)은 종종 정렬되지 않은 순서로 되어 있어 보조 인덱스를 최신 상태로 유지하기 위해 상당한 I/O가 필요함
◦
체인지 버퍼는 관련 페이지가 버퍼 풀에 없을 때 보조 인덱스 항목의 변경 사항을 캐시하여, 페이지를 디스크에서 즉시 읽지 않음으로써 비용이 많이 드는 I/O 작업을 피함
◦
캐시된 변경 사항은 페이지가 버퍼 풀에 로드될 때 병합됨
◦
업데이트된 페이지는 나중에 디스크에 플러시됨
◦
InnoDB 메인 스레드는 서버가 거의 유휴 상태일 때와 느린 종료 중에 캐시된 변경 사항을 병합함
•
효율성
◦
디스크 읽기 및 쓰기를 줄일 수 있기 때문에 변경 버퍼링은 I/O 바운드 작업 부하에 도움이 됨
▪
예를 들어, 대량 삽입과 같은 높은 볼륨의 DML 작업이 있는 애플리케이션에 도움
◦
체인지 버퍼는 버퍼 풀의 일부를 차지하여 데이터 페이지를 캐시할 수 있는 메모리를 줄임
▪
체인지 버퍼링을 비활성화는게 유용할 수 도 있음 (예. 테이블에 보조 인덱스가 상대적으로 적은 경우)
•
체인지 버퍼링 설정
◦
innodb_change_buffering 시스템 변수
▪
all: 모든 인덱스 관련 작업 버퍼링
▪
none: 버퍼링 하지않음
▪
insert: Insert 버퍼링
▪
deletes Delete 버퍼링
▪
changes: Insert, Delete 버퍼링
▪
purges: 인덱스 아이템을 영구적으로 삭제하는 작업만 버퍼링 (백그라운드 작업)
•
체인지 버퍼 최대 크기 구성
◦
innodb_change_buffer_max_size 시스템 변수
▪
기본 값: 25 / 최대값 50
▪
동적으로 변경 가능
3.3. 체인지 버퍼 모니터링
•
체인지 버퍼가 사용중인 메모리 크기
SELECT EVENT_NAME, CURRENT_NUMBER_OF_BYTES_USED
FROM performance_schema.memory_summary_global_by_event_name
WHERE EVENT_NAME= 'memory/innodb/ibuf0ibuf';
+---------------------------+------------------------------+
| EVENT_NAME | CURRENT_NUMBER_OF_BYTES_USED |
+---------------------------+------------------------------+
| memory/innodb/ibuf0ibuf | 144 |
+---------------------------+------------------------------+
SQL
복사
•
체인지 버퍼 관련 오퍼레이션 횟수
SHOW ENGINE INNODB STATUS;
-------------------------------------
INSERT BUFFER AND ADAPTIVE HASH INDEX
-------------------------------------
Ibuf: size 1, free list len 0, seg size 2, 0 merges
merged operations:
insert 0, delete mark 0, delete 0
discarded operations:
insert 0, delete mark 0, delete 0
SQL
복사