

List
Search







1. 인덱스란?
1.1. 정의 및 특징
•
원본 데이터를 빠르게 검색해서 조회하기 위해 컬럼 값을 주어진 순서로 미리 정렬해서 보관
•
데이터의 저장 (INSERT, UPDATE, DELETE) 성능을 희생하고 대신 데이터 읽기 속도를 높이는 기능
1.2. 분류
•
역할
◦
프라이머리 키 (클러스터링 인덱스)
◦
세컨더리 인덱스
•
저장 방식
◦
B-Tree 인덱스
◦
Hash 인덱스
•
중복 허용 여부
◦
유니크 인덱스
◦
유니크하지 않은 인덱스
•
기능
◦
전문 검색용 인덱스
◦
공간 검색용 인덱스
2. B-Tree 인덱스
•
컬럼의 원래 값을 변형 시키지 않고 인덳 구조체 내에서는 항상 정렬된 상태 유지
•
DMBS는 일반적으로 B-Tree의 변형인 B+-Tree / B*-Tree 사용
2.1. 구조 및 특성
•
트리 구조
◦
루트 노드 → 브랜치 노드 → 리프 노드
•
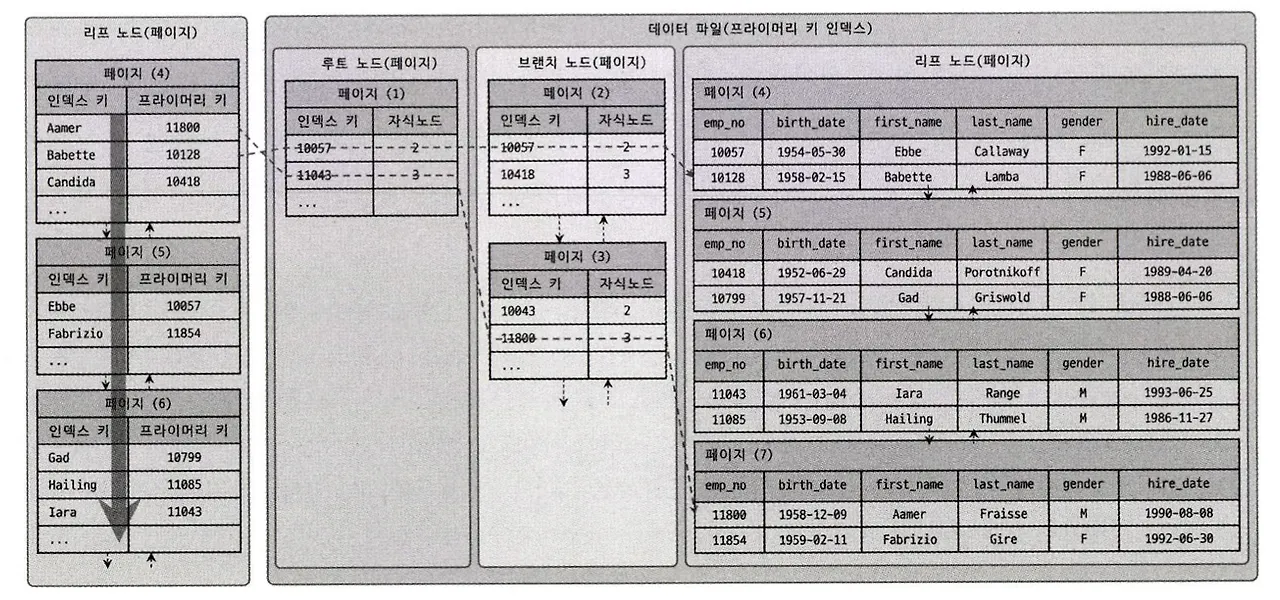
리프 노드
◦
실제 데이터 레코드를 찾아가기 위한 주소값을 가지고 있음
•
프라이머리 키 (클러스터링 인덱스)
◦
ROWID(물리적 주소값) 역할
◦
리프 노드 레코드 조회
•
세컨더리 인덱스
◦
프라이머리 키를 주소처럼 사용하므로 논리적 주소를 가짐
◦
리프 노드에 저장된 프라이머리 키를 검색 → 파라이머리 키 인덱스 검색 → 리프 노드 레코드 조회
▪
B-Tree를 두번 검색해야 데이터 조회 가능
2.2. 인덱스 키 추가 / 삭제 / 변경 / 검색
•
인덱스 키 추가
◦
저장될 키 값 이용하여 저장될 위치 검색 → 리프노드에 저장
◦
리프 노드 과포화인 경우 → 리프 노드 분리
◦
이러한 작업 탓에 쓰기 비용이 많이 드는 편
◦
cf) InnoDB 스토리지 엔진
▪
체인지 버퍼를 이용하여 추가 작업 지연 처리 가능
•
인덱스 키 삭제
◦
해당 키 값이 저장된 리프 노드 찾아 삭제 마크 처리
◦
디스크의 실제 마스킹 처리는 버퍼링되어 지연 처리 가능
•
인덱스 키 변경
◦
키 값 삭제 + 추가
•
인덱스 키 검색
◦
트리 탐색 (루트 → 리프 노드까지 검색)
◦
SELECT / UPDATE / DELETE 할때 사용
2.3. B-Tree 인덱스 사용에 영향을 미치는 요소
2.3.1. 인덱스 키 값의 크기
•
Page / Block
◦
정의
▪
디스크에 저장하는 가장 기본 단위
▪
디스크의 모든 읽기/쓰기 작업의 최소 작업 단위
▪
버퍼 풀에서 데이터를 버퍼링하는 기본 단위
▪
인덱스가 관리 되는 단위
◦
크기
▪
innodb_page_size 시스템 변수로 4KB ~ 64 KB 사이 값 선택 가능
▪
기본 값은 16KB
•
인덱스 페이지 내 키 값 구성 예시
◦
인덱스 페이지 크기: 16KB
◦
인덱스 키 값: 28 Byte
▪
인덱스 키 영역: 16 Byte
▪
자식 노드 주소 영역: 12 Byte
◦
한 인덱스 페이지 내 키 저장 갯수
▪
16*1024/(28) = 585개
•
인덱스를 구성하는 키값의 크기에 따라 디스크 조회 횟수 & 인덱스 크기가 늘어남
2.3.2. B-Tree 깊이
•
인덱스 키 값 크기 증가 → 인덱스 페이지에 담을 수 있는 인덱스 키 값 갯수 감소
→ B-Tree 깊이 증가 → 디스크 읽기 증가
2.3.3. 기수성(카디널리티)
•
정의
◦
모든 인덱스 키 값 가운데 유니크한 값의 수
•
예)
◦
전체 인덱스 키 값 100개 & 유니크한 값 10개 → 카디널리티 10
•
카디널리티 증가 → 검색 범위 감소 → 성능 향상
2.3.4. 읽어야할 레코드 건 수
•
옵티마이저: 인덱스를 통해 레코드 1건을 조회 비용 = 디스크에서 직접 조회 비용 X 4~5배 예측
•
인덱스의 손익 분기점 20~25%로 판단
•
인덱스를 통해 읽어야할 레코드 건수 (옵티마이저가 판단한 예측 건수)가 전체 테이블 레코드의 20~25%를 넘어서면 인덱스를 사용하지 않음 → 풀 스캔 후 필터링 처리
•
예) 전체 레코드 100만 건 중 50만건을 읽어야하는 경우는 인덱스 사용 X
2.4. 데이터 읽기 (1) - 단일 컬럼 인덱스
•
MySQL 스토리지 엔진이 B-Tree 인덱스를 이용하는 방법
◦
인덱스 레인지 스캔
◦
인덱스 풀 스캔
◦
루스(Loose) 인덱스 스캔
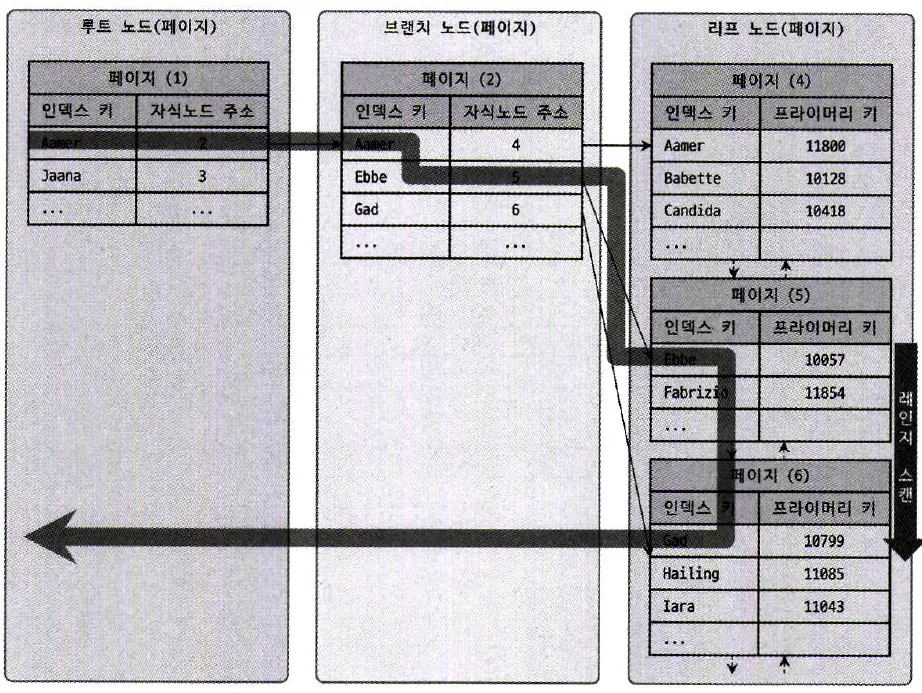
2.4.1. 인덱스 레인지 스캔
•
정의
◦
인덱스를 통해 한건/한건 이상을 읽는 경우
◦
검색해야할 인덱스의 범위가 결정 되었을 때 사용하는 방식
◦
인덱스는 자체적으로 정렬되어있기 때문에 정렬된 상태로 레코드를 가져옴
•
예시)
◦
실제 인덱스만 읽는 경우
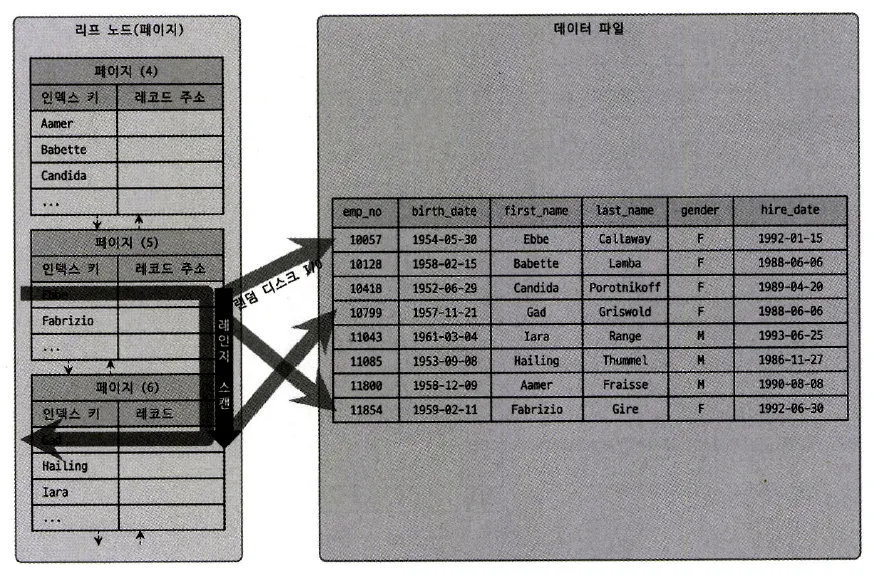
◦
인덱스를 스캔하며 실제 데이터 파일의 레코드를 읽는 경우
▪
리프 노드에 저장된 레코드 주소로 데이터 파일의 레코드를 읽어옴
▪
레코드 한건 한건 단위로 랜덤 I/O가 한번씩 일어남 → 인덱스를 통해 읽어야할 데이터 레코드 수가 20~25%를 넘어서면 직접 테이블의 데이터를 읽는것이 더 효율적
•
과정
1.
인덱스 탐색 (Index seek)
•
인덱스에서 조건을 만족하는 값이 저장된 유치를 찾음
2.
인덱스 스캔 (Index scan)
•
1번에서 탐색된 위치부터 필요한 만큼 인덱스를 차례대로 읽음
•
1번과 2번을 합쳐서 인덱스 스캔이라고도 함
3.
2번에서 읽어들인 인덱스 키와 레코드 주소를 이용해 레코드가 저장된 페이지를 가져와 레코드 읽음
•
cf) 커버링 인덱스
◦
3번과정을 거치지 않고, 인덱스 자체에서 처리가능한 인덱스
◦
실제 디스크의 레코드를 읽지 않기떄문에 랜덤 I/O가 줄어들고 성능이 빨라짐
mysql> SHOW GLOBAL STATUS LIKE 'Handler%';
+----------------------------+-------+
| Variable_name | Value |
+----------------------------+-------+
| Handler_read_first | 41 | // 인덱스의 첫번째 레코드 읽은 수
| Handler_read_last | 0 | // 인덱스의 마지막 레코드 읽은 수
| Handler_read_key | 1728 | //
| Handler_read_next | 4045 | // 2번 단계로 읽은 레코드 건수 (인덱스 정순으로)
| Handler_read_prev | 0 | // 2번 단계로 읽은 레코드 건수 (인덱스 역순으로)
+----------------------------+-------+
SQL
복사
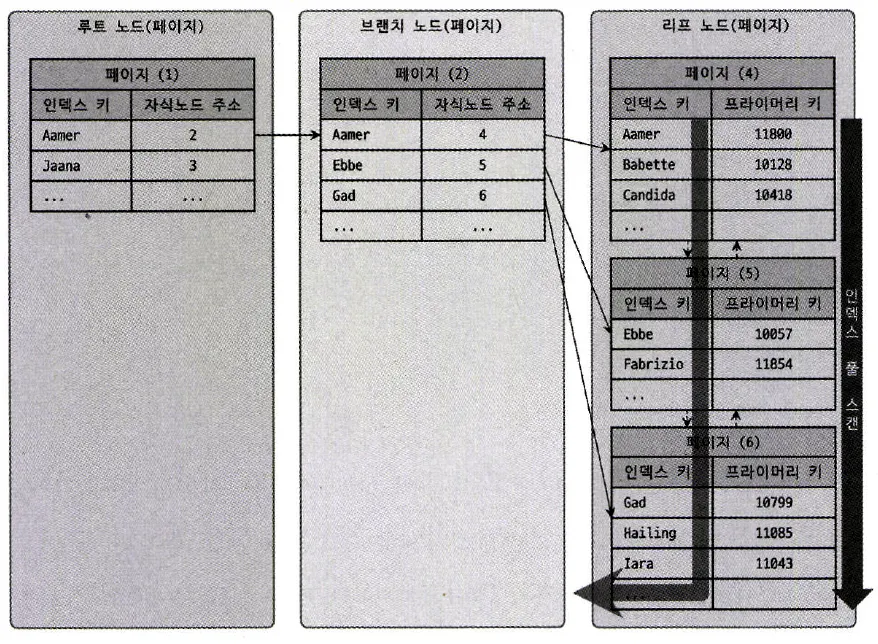
2.4.2. 인덱스 풀 스캔
•
정의
◦
인덱스를 처음부터 끝까지 모두 읽는 방식
◦
쿼리의 조건절에서 사용된 컬럼이 인덱스의 첫번째 컬럼이 아닌 경우 사용
◦
쿼리가 인덱스에 명시된 컬럼만으로 조건을 처리할 수 있는 경우 사용
•
예시)
2.4.3. 루스(Loose) 인덱스 스캔
•
인덱스를 얼마나 밀도있게 읽냐에 따른 분류
◦
타이트(Tight) 인덱스 스캔
▪
인덱스 레인지 스캔
▪
인덱스 풀 스캔
◦
루스(Loose)인덱스 스캔
•
정의
◦
느슨하게 또는 듬성듬성 인덱스를 읽는 것
◦
인덱스 레인지 스캔과 비슷하게 동작하나, 중간에 필요치 않은 인덱스 키 값은 무시하고 다음으로 넘어가는 형태로 진행
◦
주로 GROUP BY 또는 MAX(), MIN() 함수에 대해 최적화할때 사용
•
예시)
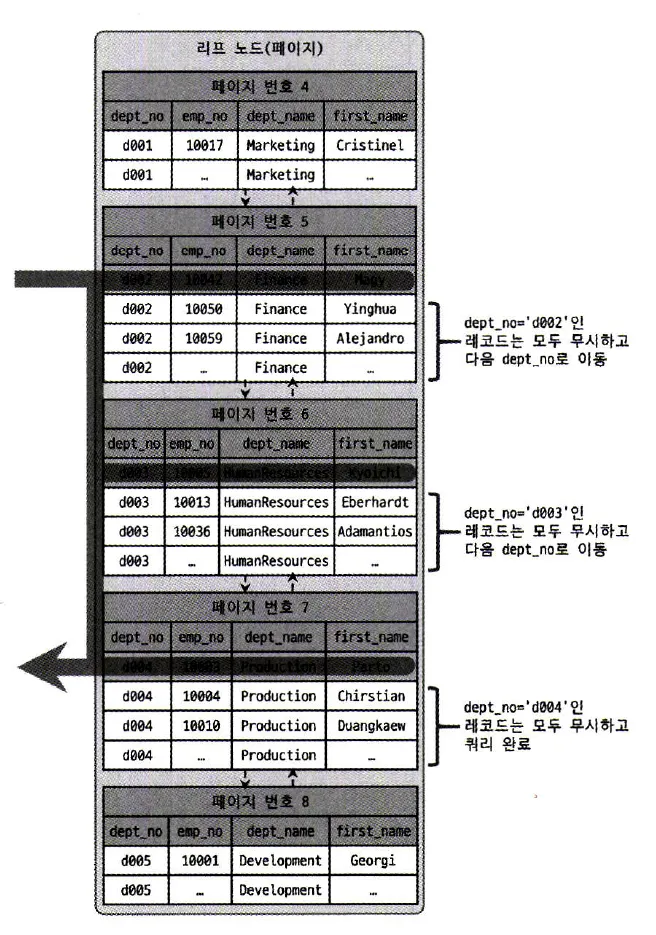
SELECT dept_no, MIN(emp_no)
FROM dept_emp
WHERE dept_no BETWEEN 'd002' AND 'd004'
GROUP BY dept_no;
SQL
복사
◦
dept_no, emp_no 두개의 컬럼으로 인덱스 생성 & 정렬
◦
옵티마이저가 조건에 만족(MIN(emp_no))하는 레코드만 찾고 다음으로 이동함
2.4.4. 인덱스 스킵 스캔
•
정의 및 특징
◦
인덱스의 선행 컬럼을 무시하고 후행 컬럼만으로 검색할 수 있도록 하는 최적화 기능
◦
MySQL 8.0부터 도입된 기능으로, 주로 WHERE 절에 선행 컬럼이 없이 후행 컬럼만 있는 경우에 사용
◦
이를 통해 인덱스를 범위로 스캔하는 대신, 특정 값을 건너뛰면서 더 효율적으로 검색할 수 있음
•
예시)
◦
gender와 birth_date 두 컬럼으로 인덱스를 만들었다고 가정
◦
기존에는 gender가 WHERE 절에 없으면 인덱스를 사용할 수 없었음
◦
스킵 스캔을 사용하면 birth_date 조건만으로도 인덱스를 사용할 수 있게 됨
▪
다만, 풀 인덱스 스캔을 하므로 아주 효율적이라고 볼 순 없음 (테이블 풀 스캔보단 효율적)
2.5. 데이터 읽기 (2) - 다중 컬럼 인덱스
•
정의
◦
여러 개의 컬럼을 결합하여 하나의 인덱스를 구성하는 방식
•
특징
◦
MySQL에서 두 개 이상의 컬럼을 포함하는 인덱스는 흔히 사용되며, 다중 칼럼 인덱스를 사용하면 쿼리 성능을 크게 개선할 수 있음
◦
다만, 이때 인덱스에 정의된 컬럼의 순서가 매우 중요함.
◦
첫 번째 컬럼이 먼저 정렬되고, 그 다음 두 번째 컬럼이 첫 번째 컬럼에 의존해서 정렬되는 구조임
•
예시)
◦
(emp_no, dept_no)라는 다중 칼럼 인덱스가 있을 때, emp_no로 검색하고 dept_no로 검색하는 것이 가능하나, dept_no만으로는 인덱스를 제대로 활용할 수 없음
◦
다중 칼럼 인덱스의 각 칼럼은 순서에 따라 효율성이 달라짐
2.6. 정렬 및 스캔 방향
2.6.1. 정렬
•
정의 및 특징
◦
B-Tree 인덱스는 기본적으로 오름차순 또는 내림차순으로 정렬되며, 인덱스를 생성할 때 이를 설정할 수 있음
◦
MySQL 5.7까지는 인덱스 컬럼마다 정렬 순서를 다르게 설정할 수 없었지만, MySQL 8.0부터는 각 컬럼마다 오름차순과 내림차순을 혼합하여 설정할 수 있음
•
예시)
◦
team_name ASC, user_score DESC와 같은 인덱스를 생성 가능
2.6.2. 스캔 방향
•
쿼리 실행 시에는 인덱스의 스캔 방향이 중요
•
오름차순으로 정렬된 인덱스도 역순으로 스캔하면 내림차순 정렬 효과를 얻을 수 있음
•
MySQL 옵티마이저는 쿼리의 실행 계획에 따라 인덱스를 순방향 또는 역방향으로 스캔하여 성능을 최적화함