
들어가기 앞서
현재 재직중인 회사에서는 MySQL을 메인 RDB로 사용하며, 대부분의 테이블에서 UUID(v4)를 PK로 채택하여 사용하고 있다. 전역고유성, 벙렬 데이터 생성, 보안성 등을 고려할 때, UUID를 PK로 쓰는 것이 많은 개발자들 상에서 보편화되어있다.
UUID를 PK로 사용할 경우 MySQL 내부적으로 재정렬을 하기 때문에 Insert 성능이 저하될 수 있다는 것 정도는 알고 있었는데, 최근들어 Real MySQL 8.0 책을 읽고 공부하면서 어떠한 이유로 성능 이슈 등이 발생하는지를 더 깊게 파악할 수 있었다.


이번 포스팅을 통해 InnoDB의 클러스터링 인덱스가 어떻게 동작하고, UUID를 클러스터링 인덱스를 썼을때 어떠한 문제가 발생하는지, 그리고 어떤 대안들이 있는지 살펴보도록 하자.
1. InnoDB 클러스터링 인덱스
UUID에 대해 살펴보기 전에 MySQL InnoDB의 클러스터링 인덱스가 무엇이고 어떻게 동작하는지를 살펴보자
1.1. 클러스터링 인덱스의 정의
•
기본 키(Primary Key)를 기준으로 데이터가 물리적으로 정렬된 상태로 저장된 인덱스
•
테이블의 실제 데이터 행이 클러스터링 인덱스에 저장되어 있으며, 기본 키 값에 따라 정렬됨
•
InnoDB 스토리지 엔진에서만 사용 가능
•
클러스터링 인덱스는 하나의 테이블에만 적용될 수 있음
1.2. 클러스터링 인덱스의 작동 방식
•
기본 키를 기준으로 데이터 정렬
◦
클러스터링 인덱스는 B-Tree 구조로, 기본 키를 기준으로 데이터를 자동으로 정렬
◦
테이블에 데이터를 삽입하면, 기본 키 값에 따라 적절한 위치에 저장
◦
물리적으로도 기본 키 순서대로 정렬
•
데이터와 인덱스 결합
◦
인덱스의 리프 노드 자체에는 테이블의 실제 데이터를 포함하고 있음
◦
따라서 기본 키를 통해 조회할 때는 추가적인 조회 작업 없이 데이터를 바로 가져올 수 있음
◦
InnoDB의 클러스터링 인덱스도 사실상 B-Tree 구조로 관리됨
◦
예시)
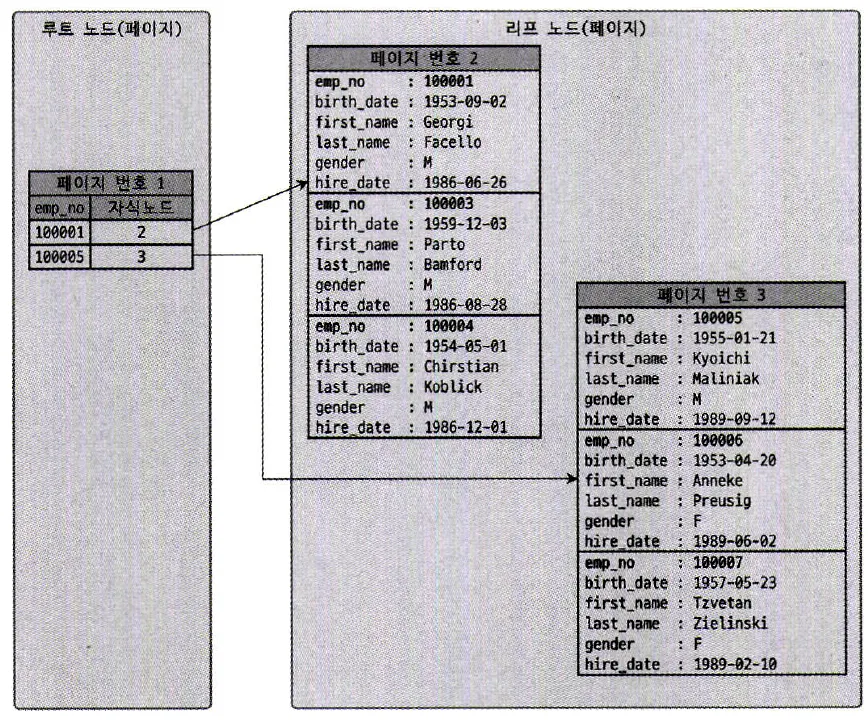
Real MySQL 8.0 1권 그림 8.25 클러스터링 인덱스의 구조
1.3. 클러스터링 인덱스의 특징
•
하나의 테이블에 하나의 클러스터링 인덱스
◦
클러스터링 인덱스는 테이블당 하나만 존재할 수 있으며, 이는 기본 키를 기준으로 생성됨
•
빠른 기본 키 조회
◦
기본 키를 통해 조회할 때, 클러스터링 인덱스는 직접 데이터에 접근할 수 있어 성능이 매우 빠름
◦
기본 키로 조회할 경우, 추가적인 인덱스를 참조할 필요가 없기 때문에 효율적
•
디스크 I/O에 많은 영향
◦
클러스터링 인덱스는 기본 키 값에 따라 데이터가 물리적으로 정렬됨
◦
비순차적인 값이 삽입되면 데이터가 재배치되거나 페이지 분할이 발생할 수 있음. 특히 UUIDv4처럼 랜덤한 값이 기본 키로 사용될 때, 이러한 성능 저하가 심화될 수 있음
◦
반대로 기본 키 값이 순차적으로 증가할 경우(예: AUTO_INCREMENT), 데이터가 물리적으로 연속된 위치에 저장되므로 디스크 I/O가 효율적임
1.4. 클러스터링 인덱스와 Auto Increment
•
Auto Increment 값을 기본키로 쓰는 경우, 기본키가 순차적으로 증가하여 클러스터링 인덱스가 물리적으로 정렬되며 데이터가 물리적으로 연속된 위치에 저장됨
•
따라서, 데이터가 재배치되거나 페이지 분할이 필요없으므로 Insert 성능이 뛰어남
•
cf) 자동 증가 락 (Auto Increment Lock)
◦
INSERT 작업이 동시에 실행될 때 각 작업이 고유한 자동 증가 값을 받을 수 있도록 보장
◦
순서 및 고유값은 보장되나, 기본키 값의 연속성은 보장되지 않음.
▪
예시)
•
트랜잭션 A가 AUTO_INCREMENT 값 1, 2, 3을 요청하고,
•
트랜잭션 B가 중간에 값 4를 요청했지만 롤백된 경우, 4는 사용되지 않고 다음 삽입에서 5가 할당됨
◦
innodb_autoinc_lock_mode 시스템 변수를 통해 잠금 모드를 조정 가능
2. UUID
2.1. UUID의 정의
•
UUID(Universally Unique Identifier)는 전 세계적으로 고유한 값을 생성하기 위한 표준화된 식별자
•
128비트 길이의 식별자로, 일반적으로 16바이트의 바이너리 데이터 또는 36문자의 문자열로 표현됨
◦
BINARY(16): 16바이트로 저장되며, 효율적임
◦
CHAR(36): 하이픈(-)이 포함된 문자열 형식으로 저장될 경우 36바이트를 차지함, 더 많은 공간 사용
•
UUID는 고유한 값으로 시스템 내에서 충돌 없이 식별자를 생성할 수 있어, 데이터베이스, 분산 시스템, 파일 시스템 등 다양한 곳에서 사용됨
•
UUID는 여러 버전이 있으며, 각각 다른 방법으로 고유성을 보장함
◦
주로 사용되는 UUID 버전은 UUIDv1, UUIDv4, UUIDv7
2.2. UUID의 구조
•
UUID는 128비트(16바이트)로 구성됨
◦
UUID는 128비트이기 때문에 2^128개의 고유한 값을 생성할 수 있음
◦
이는 매우 큰 수로, 중복될 가능성이 거의 없도록 보장함
•
8-4-4-4-12의 5개의 그룹으로 나누어진 문자열 형식(하이픈으로 구분)으로 표현됨
◦
이때 각 그룹은 특정한 정보를 담고 있음
•
예시) 123e4567-e89b-12d3-a456-426614174000
2.3. UUID 버전 종류
2.3.1. UUIDv1 (시간 기반 UUID)
•
구성
◦
타임스탬프와 MAC 주소를 기반으로 생성됨
◦
즉, UUID가 생성된 시간을 기록하며, 생성 시간과 네트워크 노드 정보(일반적으로 MAC 주소)를 포함
◦
시간 정보
▪
시간 정보가 UUID의 앞부분에 위치하지 않고 중간이나 뒤쪽에 위치함
▪
타임스탬프 정보가 다른 비트 필드들에 의해 나뉘어져 저장되므로, 그 자체로는 완전히 순차적 X
▪
따라서, MySQL 내장 함수인 UUID_TO_BIN() 를 통해 완전시 순차 정렬 되게 추가 작업 필요
•
장점
◦
시간이 순차적으로 증가하므로 데이터베이스나 파일 시스템에서 순차적인 삽입 성능을 제공
•
단점
◦
MAC 주소와 생성 시간이 포함되기 때문에 프라이버시 문제가 발생할 수 있음
◦
예) UUID를 통해 생성 시간이나 특정 하드웨어를 유추할 수 있음

2.3.2. UUIDv4 (랜덤 기반 UUID)
•
구성
◦
완전히 랜덤한 숫자를 기반으로 UUID가 생성됨. 총 128비트 중 약 122비트는 랜덤 값으로 채워짐
◦
3번째 그룹의 첫번째 글자는 항상 4로 되어있음
•
장점
◦
UUIDv4는 완전히 랜덤한 값으로 생성됨 → 전 세계적으로 고유한 값을 매우 높은 확률로 생성가능
•
단점
◦
랜덤 값이기 때문에, 데이터베이스에 삽입할 때 순차적이지 않아서 성능 저하가 발생할 수 있음
◦
특히, 클러스터링 인덱스를 사용하는 경우 성능이 떨어질 수 있음.

3. 클러스터링 인덱스와 UUID
여기서의 UUID는 일반적으로 제일 많이 사용되는 UUIDv4를 지칭함
3.1. UUID의 특성과 데이터 정렬
•
앞서 살펴본 것처럼, InnoDB에서 클러스터링 인덱스는 기본 키를 기준으로 테이블 데이터가 물리적으로 됨
•
따라서 기본 키가 UUID로 설정 되었다면, 테이블의 모든 레코드가 이 UUID 값에 따라 정렬됨
•
UUID는 기본적으로 랜덤하게 생성되는 값임(특히 UUID v4의 경우). 이로 인해 새로운 레코드가 삽입될 때 데이터는 자연스럽게 무작위 순서로 삽입됨
•
클러스터링 인덱스는 기본 키에 따라 데이터를 정렬된 상태로 유지하려고 하기 때문에, 삽입할 때마다 새로운 UUID 값이 클러스터링 인덱스에 맞는 위치로 삽입되면서 테이블의 데이터가 재정렬되는 오버헤드가 발생할 수 있음
3.2. UUID 사용 시의 문제점
3.2.1. 랜덤 삽입 문제
•
UUID 값이 랜덤하게 생성되어 새로운 레코드를 삽입할 때 디스크 페이지의 임의의 위치에 삽입해야 함
•
디스크 I/O 비용을 증가시키며, 페이지가 꽉찰 경우 페이지 분할 및 디스크 페이지 단편화가 발생해 성능에 부정적인 영향을 미침
•
페이지 분할
◦
UUID가 랜덤하게 삽입될 경우, 데이터는 물리적으로 정렬된 페이지에 삽입되어야 하지만, 새로운 레코드가 삽입될 위치가 기존 데이터 사이가 될 가능성이 높음
◦
InnoDB는 데이터 페이지가 꽉 차면 새로운 페이지를 생성하여 데이터를 나누는 페이지 분할(Page Split)을 수행함
▪
예를 들어, 데이터가 기존의 100번, 200번 순서로 저장되어 있는데, 새로운 UUID가 150번에 해당하는 위치로 삽입되면, InnoDB는 이 데이터를 물리적으로 저장하기 위해 페이지를 분할하고, 새로운 페이지에 데이터를 나누어 삽입함
◦
이러한 페이지 분할은 디스크 I/O 오버헤드를 발생시키고, 쓰기 성능을 저하시킴
•
디스크 페이지 단편화
◦
UUID가 랜덤하게 생성되면, 데이터가 랜덤하게 삽입되므로 디스크의 연속된 페이지에 저장되지 않고, 여러 페이지에 분산됨
◦
그 결과, 테이블에 데이터가 많이 삽입될수록 디스크 단편화가 발생하여, 읽기 성능도 저하될 수 있음. 이는 데이터가 물리적으로 흩어져 있기 때문에 디스크 접근 비용이 증가
3.2.2.클러스터링 인덱스의 비효율성
•
데이터가 랜덤하게 삽입되기 때문에, 클러스터링 인덱스의 정렬된 특성이 제대로 활용되지 않음
•
일반적으로 클러스터링 인덱스는 연속적인 값(예: 자동 증가하는 숫자)으로 정렬되어 있을 때 성능이 좋지만, UUID는 연속적인 값이 아니므로 정렬의 이점을 잃게 됨
3.2.3. 더 많은 저장 공간 사용
•
Auto Increment와 같은 정수형 ID(일반적으로 4바이트/8바이트)에 비해 더 많은 크기 (128비트) 크기의 데이터를 저장함
•
세컨더리 인덱스는 클러스터링 인덱스를 참조하게 되는데, 기본 키가 커질수록 보조 인덱스도 더 많은 저장 공간을 필요로 함
3.3. UUID 퍼포먼스 비교
•
클러스터링 인덱스에 UUID를 썼을때와 Auto Increment을 썼을때의 퍼포먼스를 비교한 레퍼런스들은 검색해보면 상당히 많음
•
그중 몇가지 예시를 살펴보면 다음과 같음
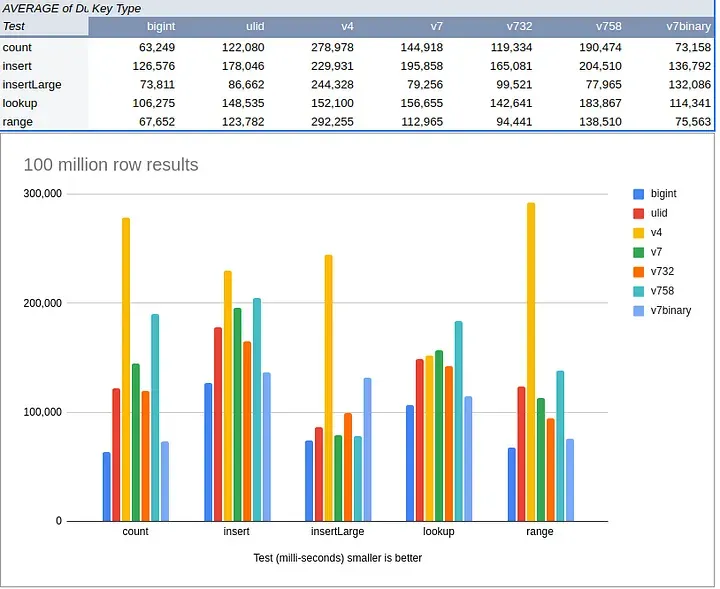
3.3.1. UUID 퍼포먼스 예시 (1)
•
데이터 생성(insert, insertLarge)
◦
UUIDv4가 Auto Increment(bigint)에 비해 퍼포먼스가 상당히 낮음
•
조회(count, range) 또한 유사함
•
자세한 내용은 원본 링크에서 확인 가능
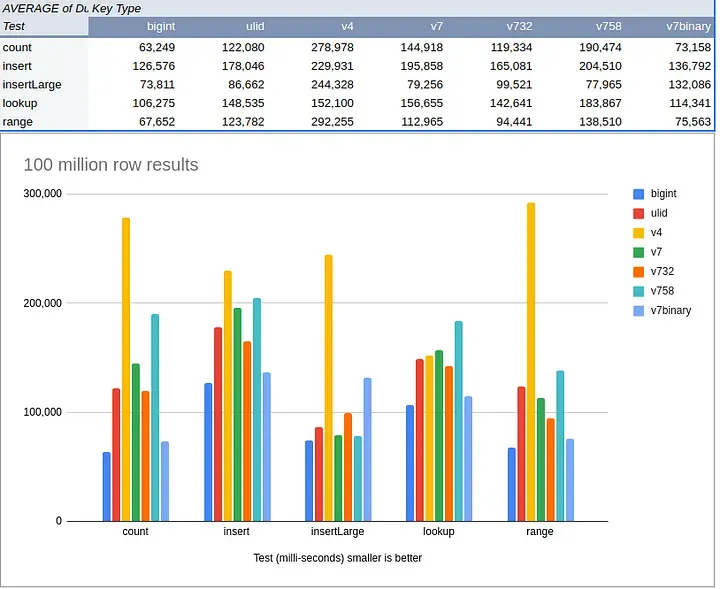
3.3.2. UUID 퍼포먼스 예시 (2)
•
2014년의 조금 오래된 예시이며, UUIDv1 을 사용했으나, 근본적인 매커니즘은 동일함
•
UUID를 사용했을 때, Auto Increment 보다 퍼포먼스가 많이 느림
•
데이터의 크기에 차이도 보임
•
자세한 내용은 원본 링크에서 확인 가능

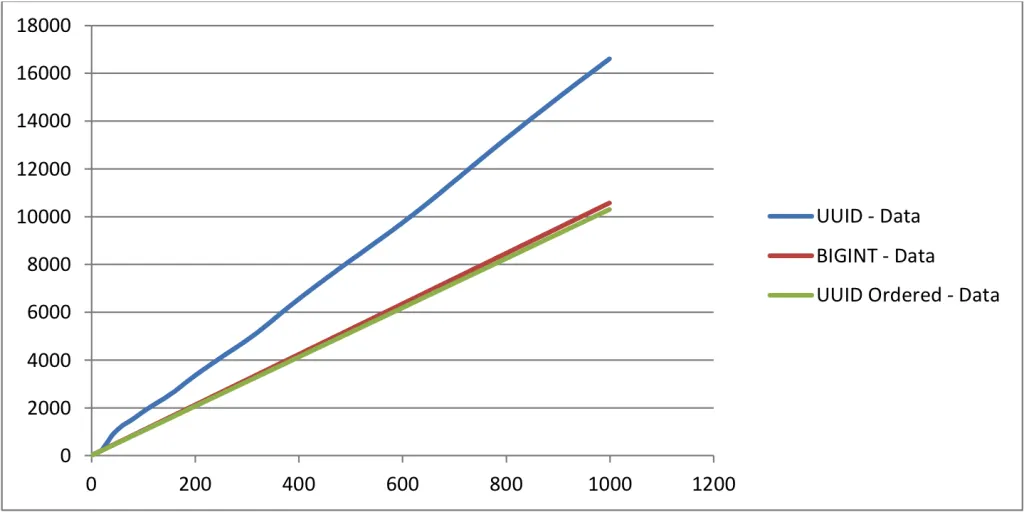
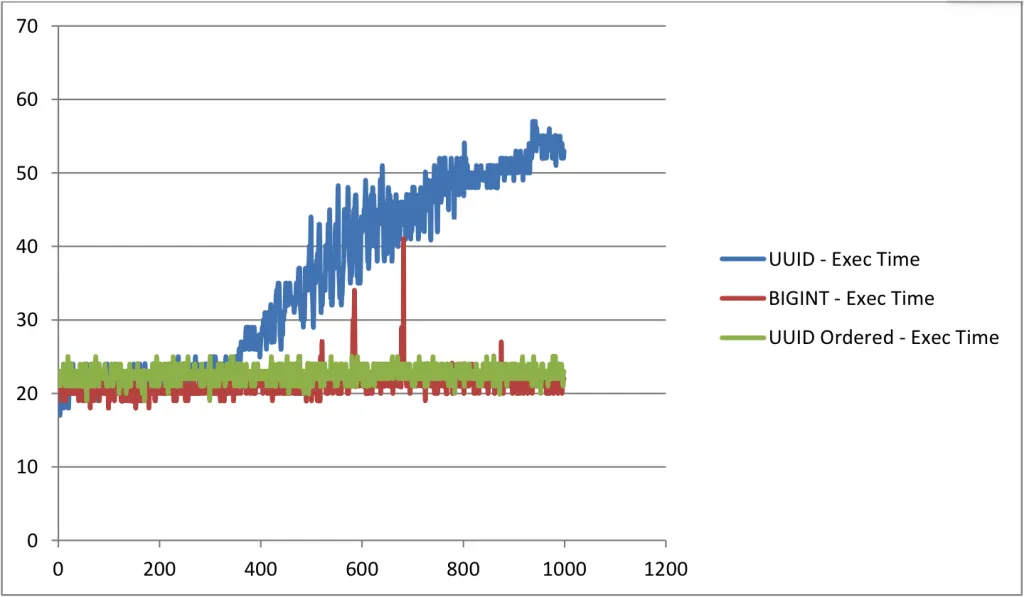
4. UUIDv4 문제 해결 방안
4.1. UUIDv1
•
UUIDv4를 대체할 수 있는 가장 쉬운 대안 중 하나
•
MySQL 내장 함수인 UUID_TO_BIN() 를 사용하면 순차적인 삽입이 이루어져 삽입 성능 향상 가능
•
다만, 2.3.1 에서 살펴본 것 처럼, MAC 주소와 타임스탬프가 포함되어 보안 문제가 있을 수 있음
•
따라서, 좋은 방안이라고 볼 순 없음
4.2. Auto Increment(PK) + UUID
4.2.1. 구성
•
Auto Increment를 Primary Key로 사용하여 삽입 성능을 최적화하고, UUID를 세컨더리 인덱스로 설정하는 방식
•
클러스터링 인덱스는 순차적으로 유지되면서도, UUID를 통한 고유성을 확보 가능
•
cf) 세컨더리 인덱스의 매커니즘
◦
세컨더리 인덱스는 기본키를 참조하는 방식으로 동작
◦
즉, 세컨더리 인덱스는 그 자체로는 실제 데이터를 포함하지 않으며, 세컨더리 인덱스가 가리키는 기본 키를 통해 다시 클러스터링 인덱스에 접근해서 데이터를 조회함 → 두번 인덱스 탐색
4.2.2. 잠재 성능 이슈
•
세컨더리 인덱스 접근 비용
◦
세컨더리 인덱스 조회 → 기본키 조회 (두번 인덱스 탐색 필요)
◦
데이터양이 많을 수록 이 과정에서 추가 디스크 I/O 발생 가능
•
클러스터링 인덱스 접근 비용
◦
세컨더리 인덱스 → 기본키를 통해 클러스터링 인덱스 재접근 진행
◦
조회 데이터양이 많을 수록 디스크 접근 비용 증가
•
캐시 사용 여부
◦
InnoDB의 버퍼 풀에 해당 페이지가 캐싱되어있는 경우, 위 이슈들의 영향을 줄어들 수 있음
◦
그러나, 여전히 메모리 상의 접근 오버헤드 존재
4.3. ULID
4.3.1. ULID의 구성
•
Universally(범용적으로) Unique(고유한) Lexicographically(사전적으로) Sortable(정렬가능한) Identifier (식별자)
•
시간 기반 순차성과 랜덤성을 결합하여, 정렬 가능한 고유 식별자를 생성하는 방식
•
128비트로 구성되어 있으며, 이는 크게 두 가지 요소로 나뉨
◦
48비트 타임스탬프
▪
순차적으로 증가
◦
80비트의 랜덤값
▪
고유성 보장
◦
예시)
01AN4Z07BY 79KA1307SR9X4MV3
|----------| |----------------|
Timestamp Randomness
48bits 80bits
JSON
복사
4.3.2. ULID의 장점
•
순차성 보장
◦
ULID는 타임스탬프 기반으로 생성되기 때문에 시간 순으로 순차적으로 정렬
◦
이로 인해 삽입 성능이 향상되며, 클러스터링 인덱스에 적합
•
UUID보다 읽기 쉬운 형식
◦
ULID는 Base32로 인코딩된 26자리 문자열
◦
UUID의 복잡한 36자리 형식보다 사람이 읽고 다루기 쉬움
•
빠른 생성
◦
ULID는 성능이 중요한 상황에서 매우 빠르게 생성될 수 있음
4.3.3. ULID의 단점
•
64비트 타임스탬프 제한
◦
ULID는 48비트 타임스탬프 필드를 사용하므로 시간 범위가 제한됨
◦
이는 약 1,089년 동안만 고유한 타임스탬프를 제공할 수 있음
◦
매우 장기적인 시스템에서는 제한적일 수 있음
•
보안성 부족
◦
ULID는 순차적으로 생성됨
◦
보안이 중요한 애플리케이션에서는 패턴을 분석하거나 예측 가능성이 문제가 될 수 있음
•
표준화되지 않은 방식
◦
MySQL이나 PostgreSQL 같은 데이터베이스는 기본적으로 ULID 생성을 지원 X
◦
서드파티 라이브러리를 사용 필요
◦
이를 통합하고 관리하는 추가적인 작업이 필요
4.4. UUIDv7
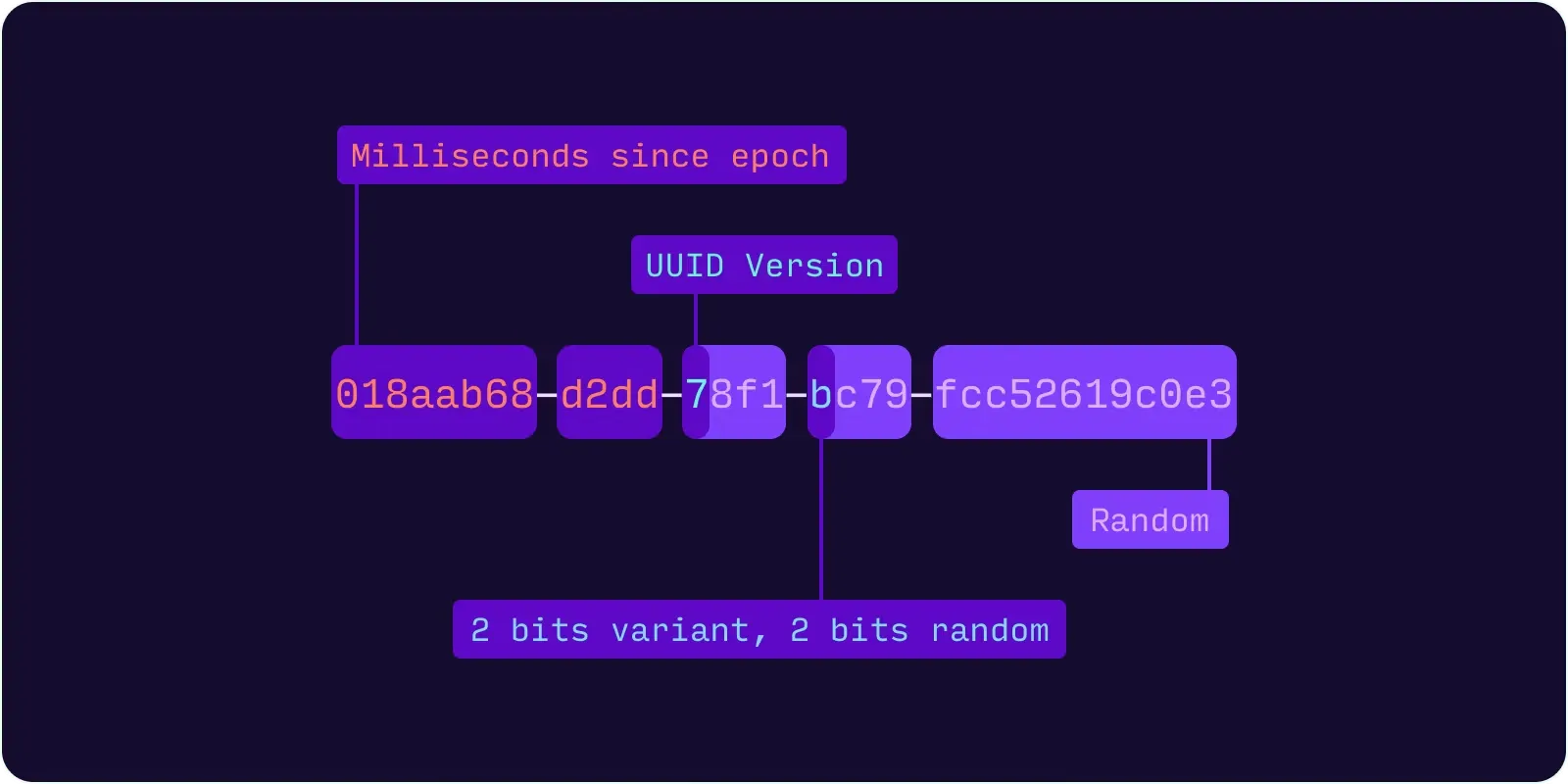
4.4.1. UUIDv7의 구성
•
128비트 (전통적인 UUID 형식)
◦
48비트 타임스탬프
▪
Unix Epoch 시간으로부터 밀리초 단위의 타임스탬프
▪
순차적으로 증가
◦
남은 80비트는 랜덤
•
공식 UUID 표준 (RFC 4122)
4.4.2. UUIDv7의 장점
•
시간 기반 순차성
◦
UUIDv7은 시간 순서에 따라 ID가 생성되므로, 삽입 성능과 정렬 성능이 크게 향상됨.
◦
UUIDv4의 비순차성 문제를 해결하고, 클러스터링 인덱스에서 삽입과 읽기 성능을 최적화 가능
•
128비트 크기
◦
UUIDv7은 128비트 크기를 유지하므로, 충돌 가능성이 매우 낮아 고유성을 충분히 보장
◦
이로 인해 기존의 UUID 시스템과 쉽게 호환 가능
•
범용성
◦
UUIDv7은 시간 기반이면서도 랜덤성을 적절히 제공
◦
보안이 중요한 시스템에서도 UUIDv4보다 더 나은 선택이 될 수 있음
4.4.3. UUIDv7의 단점
•
새로운 표준
◦
UUIDv7은 새로운 표준이기 때문에, 모든 라이브러리나 시스템에서 완전히 지원되지 않을 수 있음
◦
이로 인해 도입 초기에는 호환성 문제가 발생할 수 있음
•
타임스탬프 노출
◦
UUIDv7은 타임스탬프를 포함하므로, UUID가 생성된 시간을 쉽게 알 수 있음.
◦
만약 식별자가 보안적인 이유로 시간 정보가 노출되면 안 되는 환경이라면, 이러한 정보 노출이 문제가 될 수 있음
5. 결론
•
UUIDv1
◦
Mac주소와 타임스탬프가 모두 노출 될 수 있기때문에 좋은 대안으로 보이지 않음
•
ULID/UUIDv7
◦
기존의 UUIDv4의 단점을 보완한 새로운 식별자들로, 둘다 큰 차이가 없어 보임. 개인적으로는 UUIDv7이 공식 표준인 만큼 UUIDv7을 쓰는 것이 조금은 더 낫지 않을까 싶음
◦
3.3.1 UUID 퍼포먼스 예시 (1) 을 살펴보면 ULID/UUIDv7을 사용했을때 퍼포먼스가 UUIDv4보다 현저히 증가했음을 알 수 있음
•
Auto Increment (Int/BigInt) + UUIDv4
◦
PK로 쓰고 UUID를 세컨더리 인덱스로 쓰는 방법도 보편적으로 많이 사용되는 방법으로 보임. 그러나 UUID로 조회할때 두번의 인덱스 조회가 필요하므로 조회 성능에서 약간의 오버헤드가 발생할 수 있다고 봄
◦
이 오버헤드가 얼마나 큰지 실제 퍼포먼스를 비교해본 레퍼런스는 찾지 못했는데, 시간될 때 한번 퍼포먼스 비교를 해보는 것도 좋을 것 같음
◦
또한 ULID/UUIDv7은 타임스탬프가 여전히 노출 될 수 있어서 보안상의 이슈가 있을 수 있는데 보안이 중요한 서비스라면 이 옵션을 선택하는것도 좋아 보임

정답은 없고, 서비스의 규모와 상황에 따라 ULID/UUIDv7 또는 Auto Increment + UUID 중 하나의 대안을 선택하면 좋아 보임
