Index
Search
1. 설계 개요
•
소프트웨어 설계
◦
명세에 구현을 위한 방법을 명시
1.1. 설계 프로세스
•
반복적 프로세스
•
초기 버전을 만들고 지속적으로 수정하며 세세하게 기술
1.2. 설계 원리 - 문제의 분할
•
Divde and Conquer
•
분할 후 정복
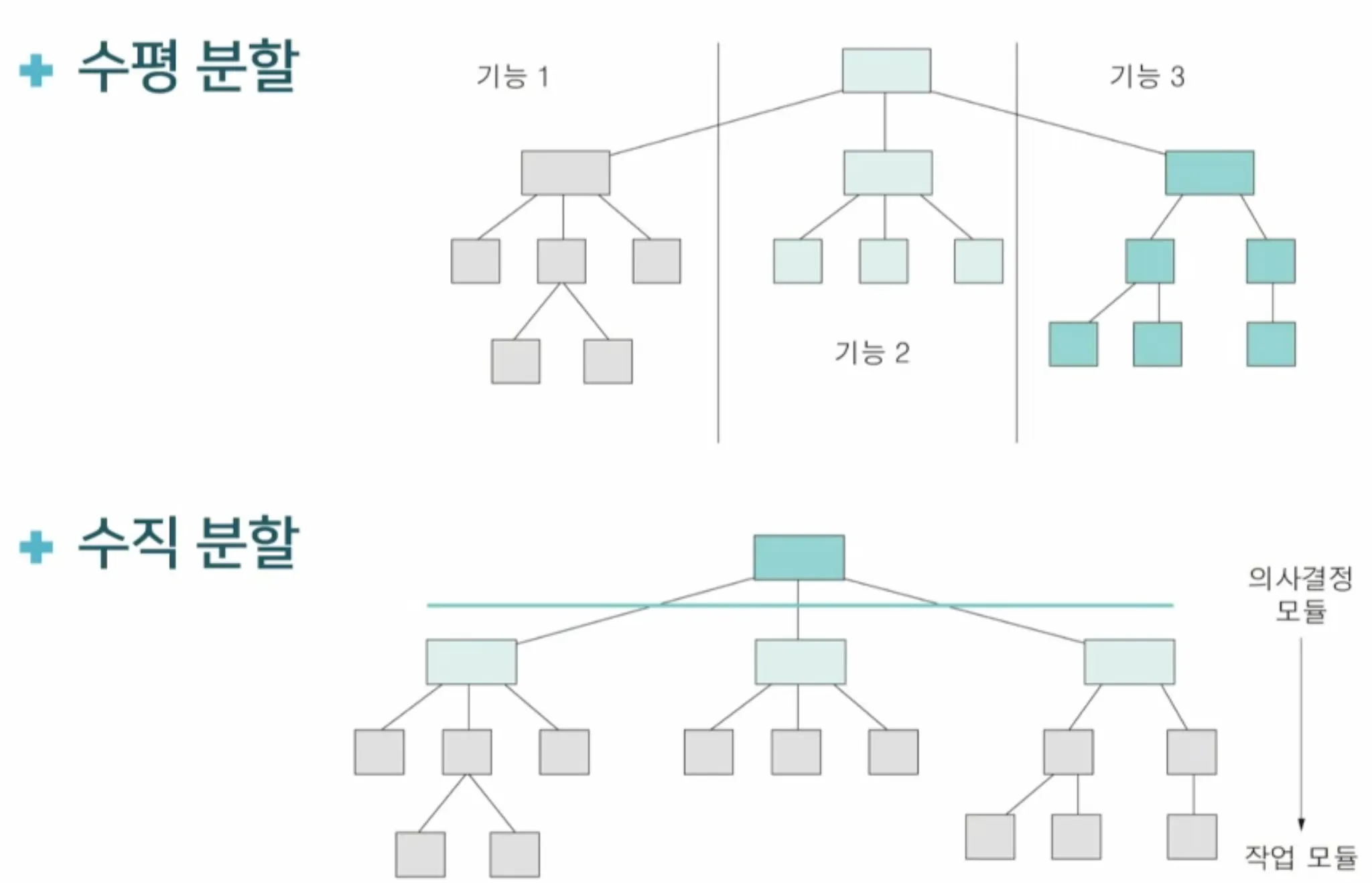
•
수평 분할
◦
기능들을 분리된 가지에 할당함
◦
주요 기능을 분리하여 수평으로 잘라서 할당
▪
입력 작업, 데이터 변환, 출력 작업
•
수직 분할
◦
제어 모듈과 작업 모듈을 위 아래로 분산
◦
상위 수준 모듈 - 제어 기능
◦
하위 모듈 - 실제 작업 수행
◦
작업 모듈이 변경되기 쉬우며 제어 무듈 변경이 되면 부작용이 큼
1.3. 설계 원리 - 추상화
•
추상화
◦
블랙박스
◦
정보 은닉
◦
내부 상세 내용 생략하고 외부 행위만 기술
•
종류
◦
기능 추상화
▪
수행하는 기능으로 모듈 명세
▪
전체를 작은 기능으로 분해 (기능 중심 분할)
◦
데이터 추상화
▪
데이터와 데이터 조작을 필요한 오퍼레이션을 함께 묶음
▪
객체 상세 내용 감추며, 공개된 오퍼레이션을 통해만 조작 가능
1.4. 설계 원리 - 하향식 / 상향식 설계
•
하향식
◦
주요 컴포넌트 → 낮은 수준 컴포넌트로 분해
◦
단계적 정제
◦
메인 모듈 부터 설계 시작
◦
새로 개발에 적합
•
상향식 설계
◦
기본 컴포넌트 머저 설계 이후 상위 수준 컴포넌트 설계
◦
기존 컴포넌트 조합하여 개발할 때 적합
2. 아키텍처 설계
•
아키텍처
◦
시스템의 구조를 정하는 것 (초기 설계)
◦
개발이 진행된 후 시스템 구조 변경이 어려우므로 아키텍처가 중요함
•
아키텍처 스타일 (패턴)
◦
유사한 애플리케이션에서 사용되는 공통적인 아키텍처 패턴
◦
미리 만들어진 시스템 설계 모델
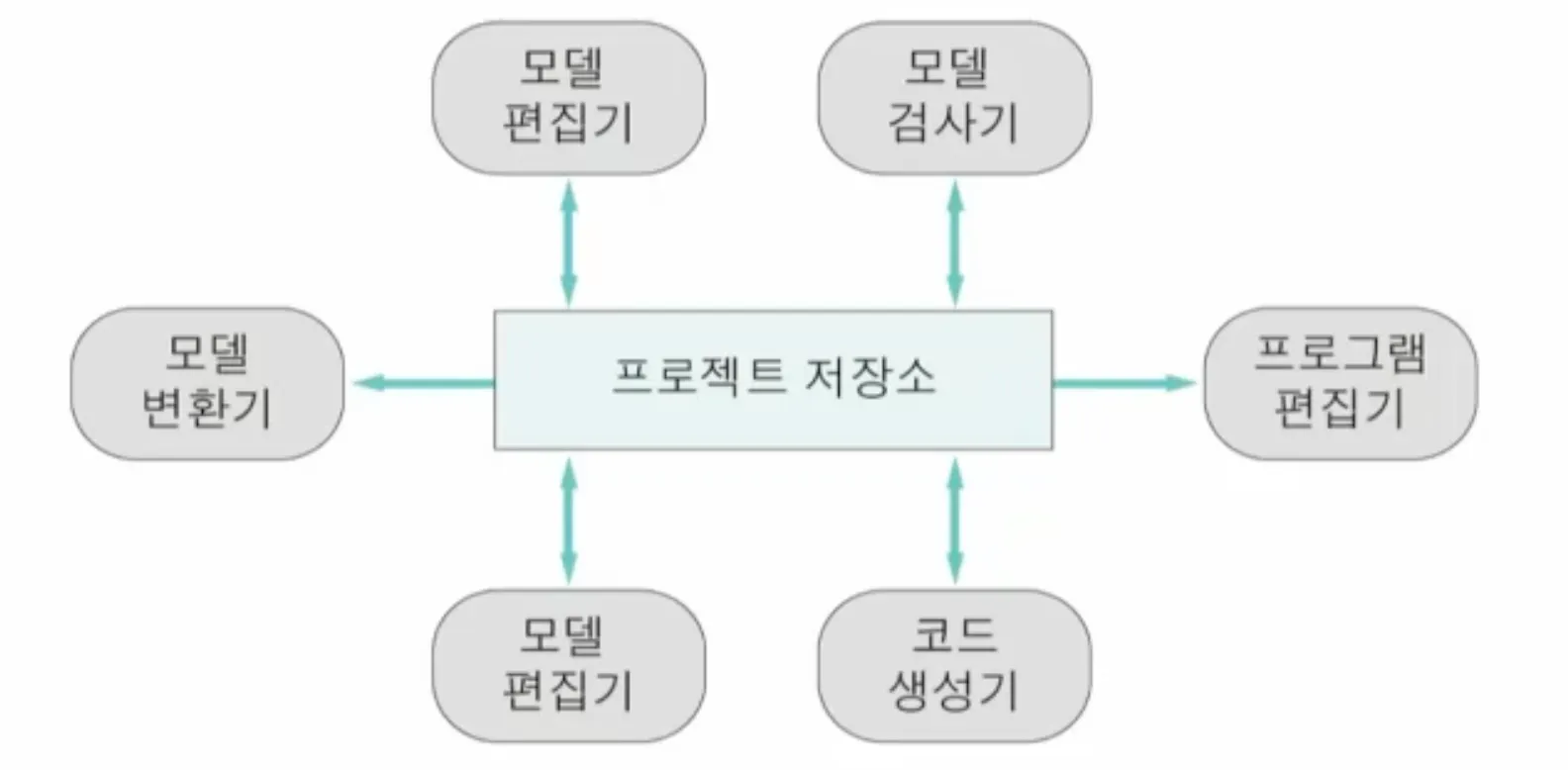
2.1. 데이터 중심 아키텍처
•
저장소 모델
•
서브 시스템 간 대규모 데이터 공유하는 소프트웨어 시스템
•
공유된 데이터베이스 기반한 아키텍처로 저장소를 통해 상호 작용
◦
서브 시스템은 중앙 통합 관리되는 데이터베이스를 통해 상호 작용
•
장점
◦
데이터 관리 효율적
◦
데이터 생성 서브시스템과 사용 서브시스템 독립적
◦
공유 데이터 모델 사용시 시스템 확장 용이
•
단점
◦
서브시스템이 공통의 데이터 모델 사용해야함
◦
중앙 저장소 성능 저하에 병목 현상발생
◦
모든 서브 시스템에 동일한 정책적용
◦
데이터 모델 변경시 큰 비용 발생
•
예시
◦
학사 관리
◦
ERP
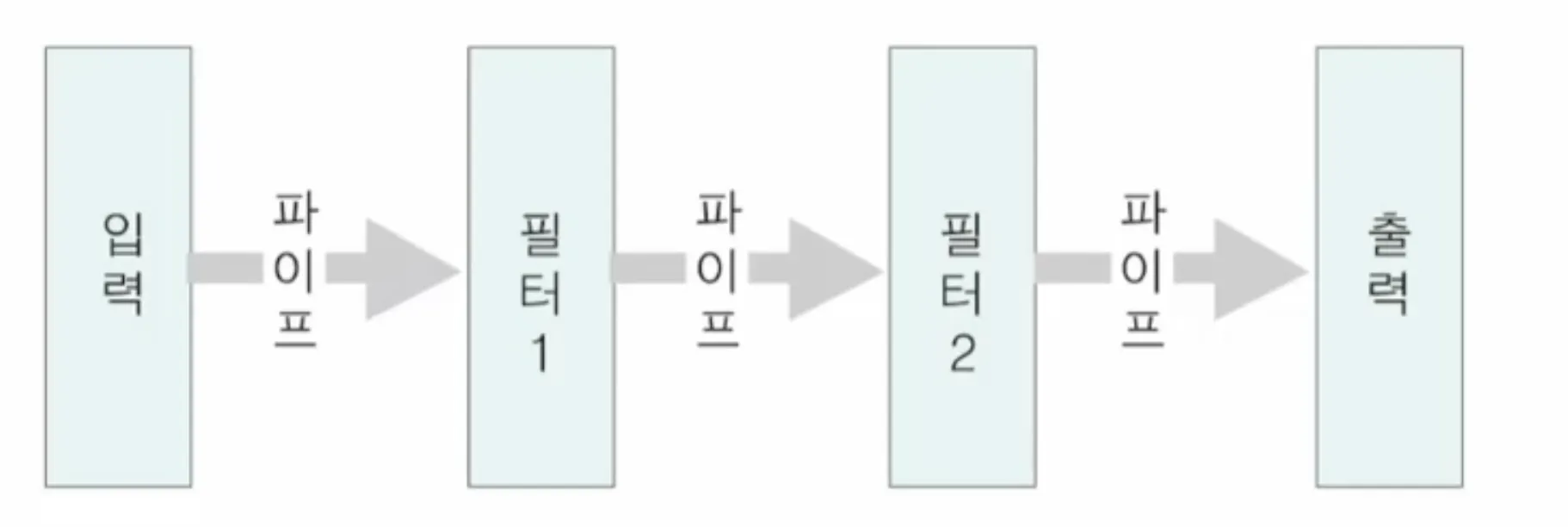
2.2. 데이터 흐름 아키텍처
•
파이프 필터 구조
•
데이터 요소에 대한 개별 변환 작업들을 연결하여 시스템 구성
•
사용자 간섭 없이 데이터 스트림에 일련의 변환 작업을 적용하는 시스템에 적합
•
구성요소들 간의 복잡한 상호작용 요구시 적합 X
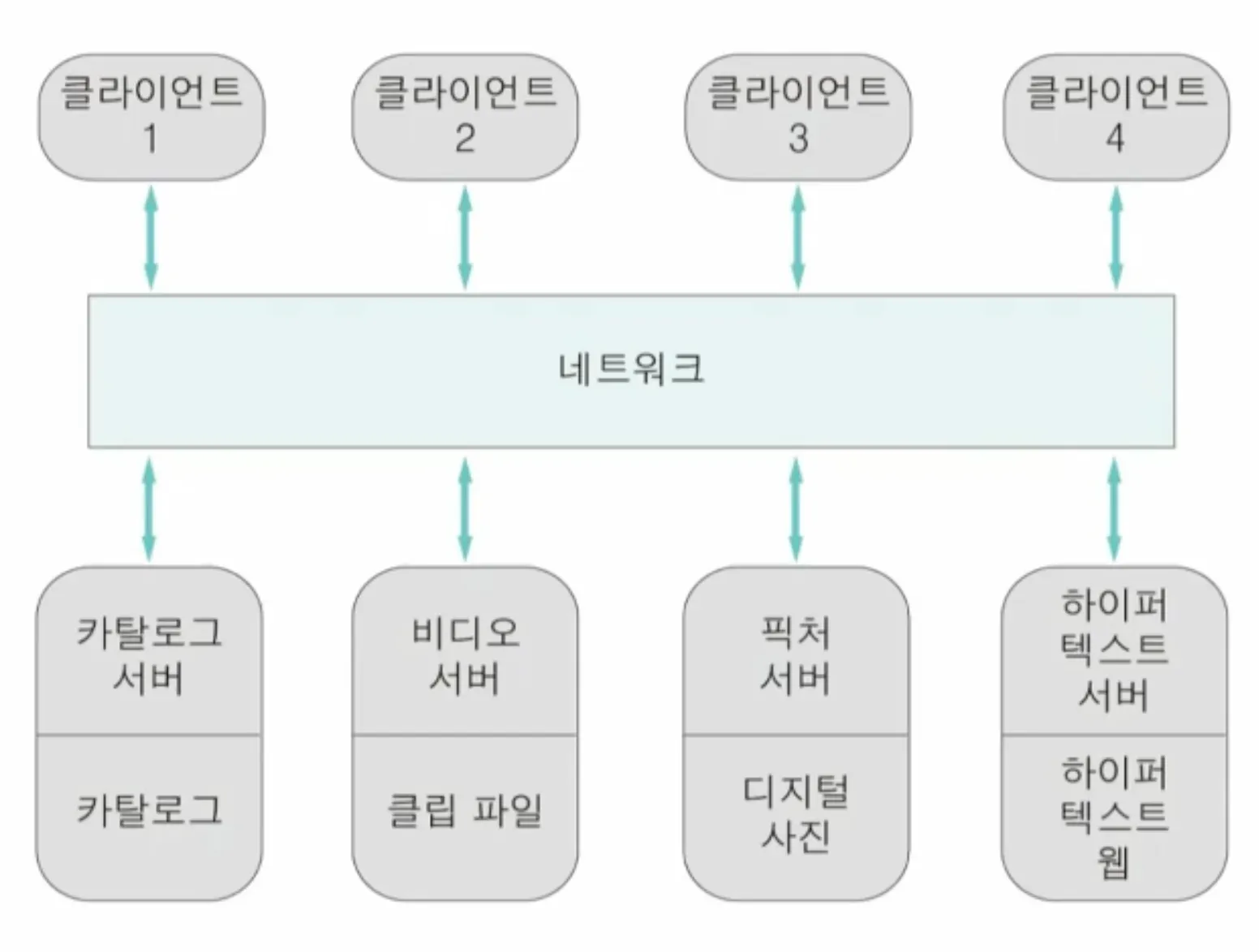
2.3. 클라이언트-서버 아키텍처
•
서버의 집합과 클라이언트들로 시스템 구성
•
분산 시스템의 아키텍처. 서버와 클라이언트는 네트워크로 연결
•
장점
◦
데이터와 데이터 처리 분산
◦
분산된 프로세스 효율적 사용 가능
◦
새로운 서버 추가 쉬움
•
단점
◦
공유 데이터 모델이 없음 → 데이터 교환 비효율적
◦
모든 서버가 각각 데이터 관리 책임 가짐
2.4. 계층형 아키텍처
•
추상 기계 모델. 시스템을 계층별로 구성
•
하위 계층이 제공하는 서비스를 상위 계층이 이용
•
특징
◦
각 계층은 특정 서비스를 제공하며 서브 시스템들의 점증적 개발 가능
◦
특정 계층의 인터페애스가 변경되면 인접 계층만 영향을 줌
◦
실제로 시스템을 계층 구조로 만들기 어려움
2.5. MVC 아키텍처
•
시스템 기능 분리
◦
도메인 지식을 관리하는 모델
◦
사용자에게 보여주는 뷰
◦
사용자와 상호작용 제어하는 컨트롤러
•
고려 사항
◦
저장소 모델의 특수한 형태
◦
하나의 모델에 대해 여러 뷰를 제공해야하는 대화형 또는 웹기반 시스템에 적합
2.6. 3계층 아키텍처
•
클라이언트-서버 모델의 개선된 형태
•
사용자 인터페이스, 애플리케잉션 로직, 저장소의 3계층으로 분리
•
layered architecture
2.7. 아키텍처와 비기능적 속성
•
소프트웨어 아키텍처는 비기능적 요구사항에 큰 영향을 줌
◦
성능 - 서브시스템 간 통신 최소화
◦
보안 - 계층형 아키텍처 사용
◦
안전성 - 안전성 요구 요소를 하나의 서브시스템에 집중
◦
가용성 - 동일 기능 컴포넌트 중복
◦
유지보수성
•
모든 것은 트레이드 오프 → 타협 필요
3. 구조적 설계
3.1. 구조적 설계
•
구조적 분석(SA)의 결과물 이용해 아키텍처 설계 및 모듈 개발
◦
데이터 흐름도(DFD)를 통해 구조도(SC)를 만듬
•
결과물
◦
구조도, 모듈 명세서, 자료사전
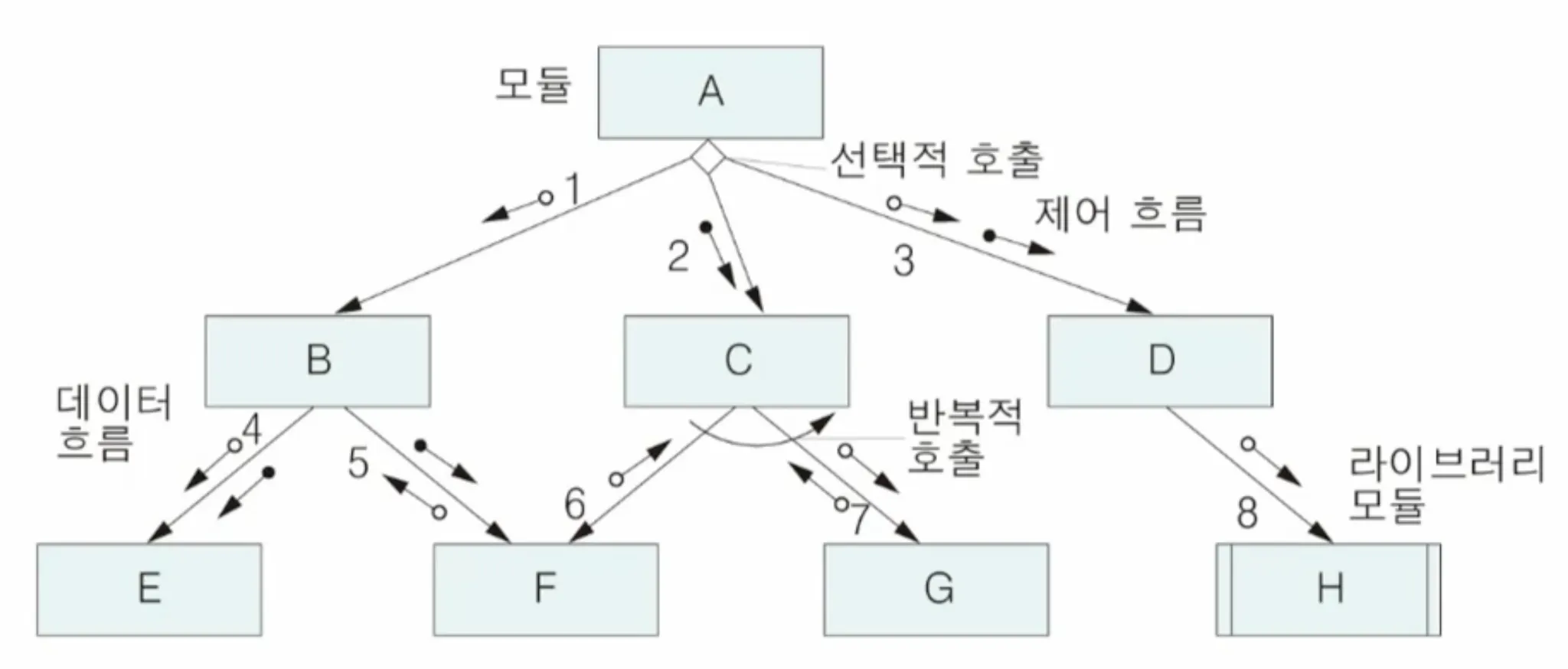
3.2. 구조도
•
모듈들의 계층 구조, 모듈의 매개 변수, 모듈들 간의 상호 연결 관계 보여줌
◦
모듈들은 블랙박스로 표현
◦
계층적으로 배열
◦
상위 모듈이 하위 모듈 호출
•
구성 요소
◦
모듈, 라이브러리 모듈
◦
데이터 흐름, 제어 흐름
◦
호출, 선택적 호출, 반복적 호출
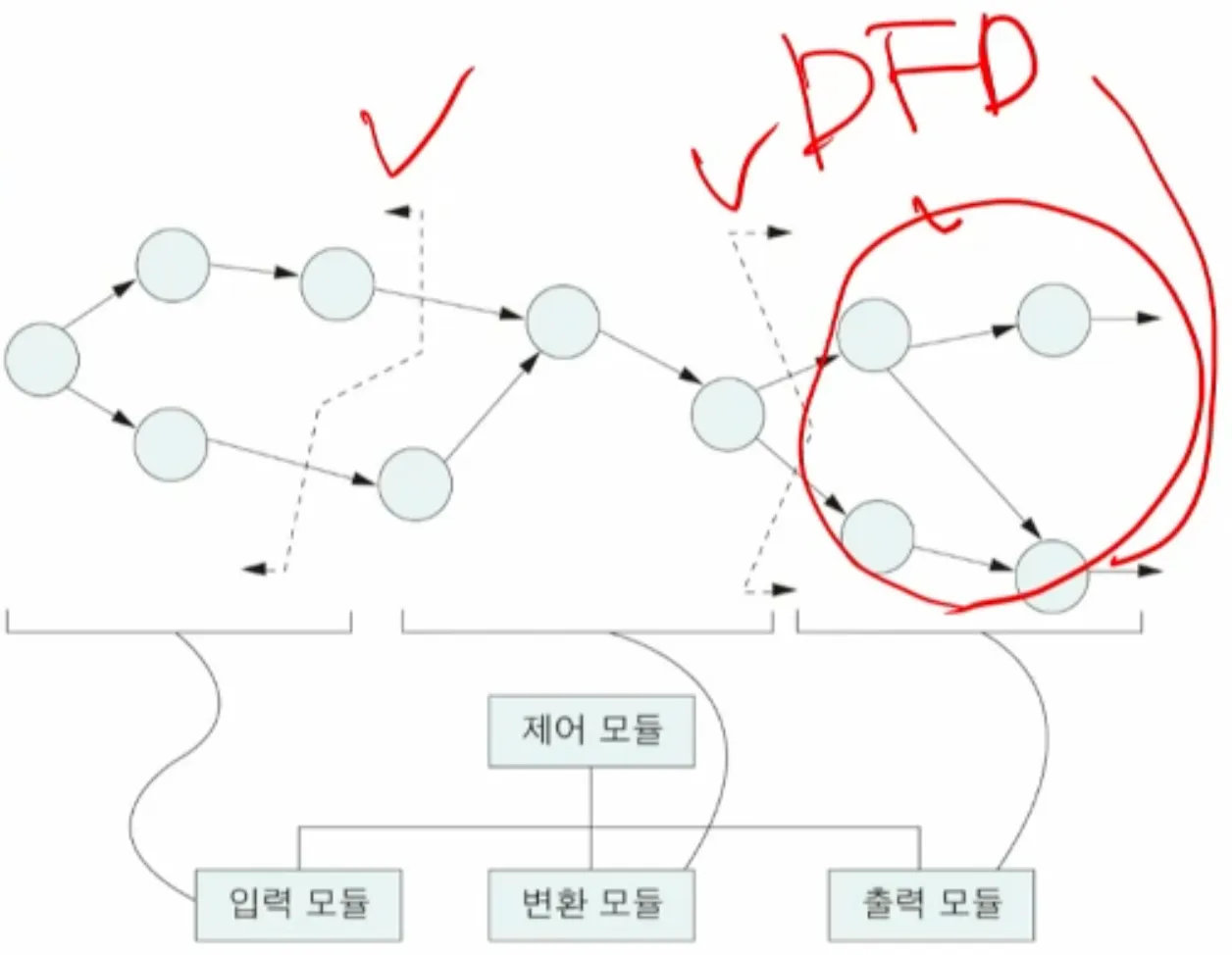
3.3. 변환 분석에 의한 구조적 설계
•
데이터 흐름의 유형이 변환 흐름인 경우 사용
•
변환 흐름은 데이터를 입력 받고, 변환/가공하고 결과를 출력하는 유형
•
변환 분석
◦
데이터 흐름도에서 입력흐름과 출력흐름의 경계 표시
◦
구조도에 입력, 변환, 출력 모듈을 제어하는 모듈을 추가로 만듦
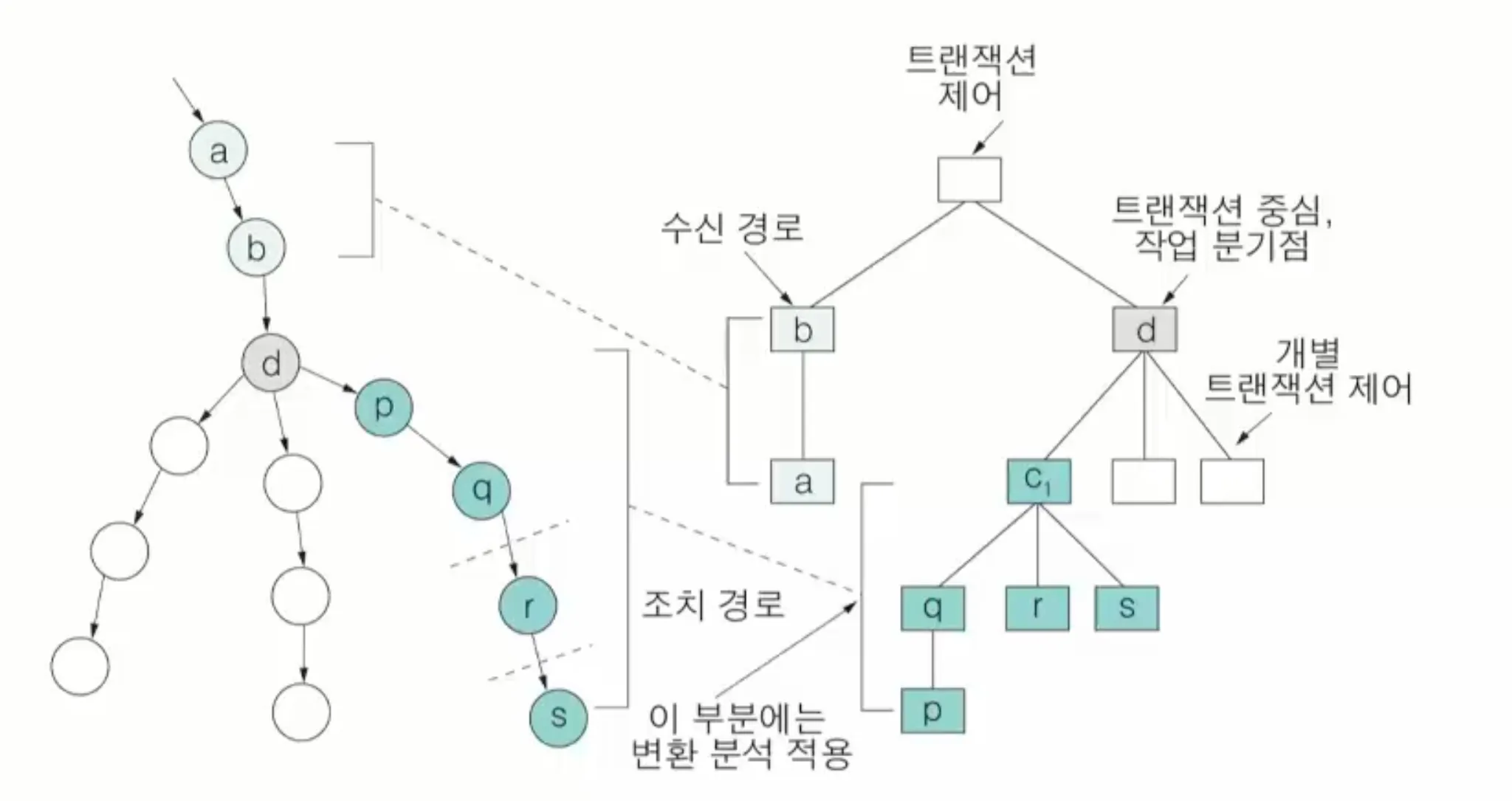
3.4. 트랜잭션 분석에 의한 구조적 설계
•
데이터 흐름의 유형이 트랜잭션 흐름인 경우 사용
•
트랜잭션 흐름은 한 프로세스에서 입력을 여러 경로의 데이터 흐름으로 유출하는 유형
◦
트랜잭션 중심 모듈은 트랜잭션의 유형을 결정하고 적덩한 모듈을 호출하는 모듈
•
트랜잭션 분석
◦
트랜잭션의 소스를 식별하고 트랜잭션 중심 모듈을 찾음
◦
전체를 제어하는 모듈을 추가
◦
데이터 수신 경로와 트랜잭션 중심에 해당하는 모듈을 하위에 위치시킴
◦
처리 부분에 있는 프로세스를 모듈로 변환
4. 상세 설계와 모듈화
4.1. 상세 설계
•
개별 모듈에서 사용되는 자료 구조와 알고리즘을 자세히 설계
•
상세 설계는 기능적 요구사항에 초점
4.2. 모듈화
•
시스템을 여러 분릴된 컴포넌트들로 나누어 구성하는 것
•
모듈화된 시스템은 잘 정의되고 관리 가능한 단위들로 구성되며 각 단위들은 잘 정의된 인터페이스를 통해 소통
•
장점
◦
구성 요소들이 기능적으로 독립적
◦
구성요소들을 독립된 단위로 문서화 가능
◦
재사용 용이
◦
테스트와 디버깅, 유지보수 작업 쉬움
4.3. 모듈의 독립성
•
모듈의 독립서응로 시스템 설계 결과 평가 가능
•
모듈 독립성 평가
◦
높은 응집력
◦
느슨한 결합도
•
결합도
◦
두 모듈간 상호 의존성 정도
•
응집도
◦
모듈을 구성하는 요소들이 기능적으로 얼마나 관련성 있는가?
◦
하난의 모듈이 가지는 기능적 집중성에 관한 척도
5. 객체지향 설계 원칙
5.1. 단일 책임 원칙 - SRP
•
모든 클래스는 하나의 책임만 가져야 한다.
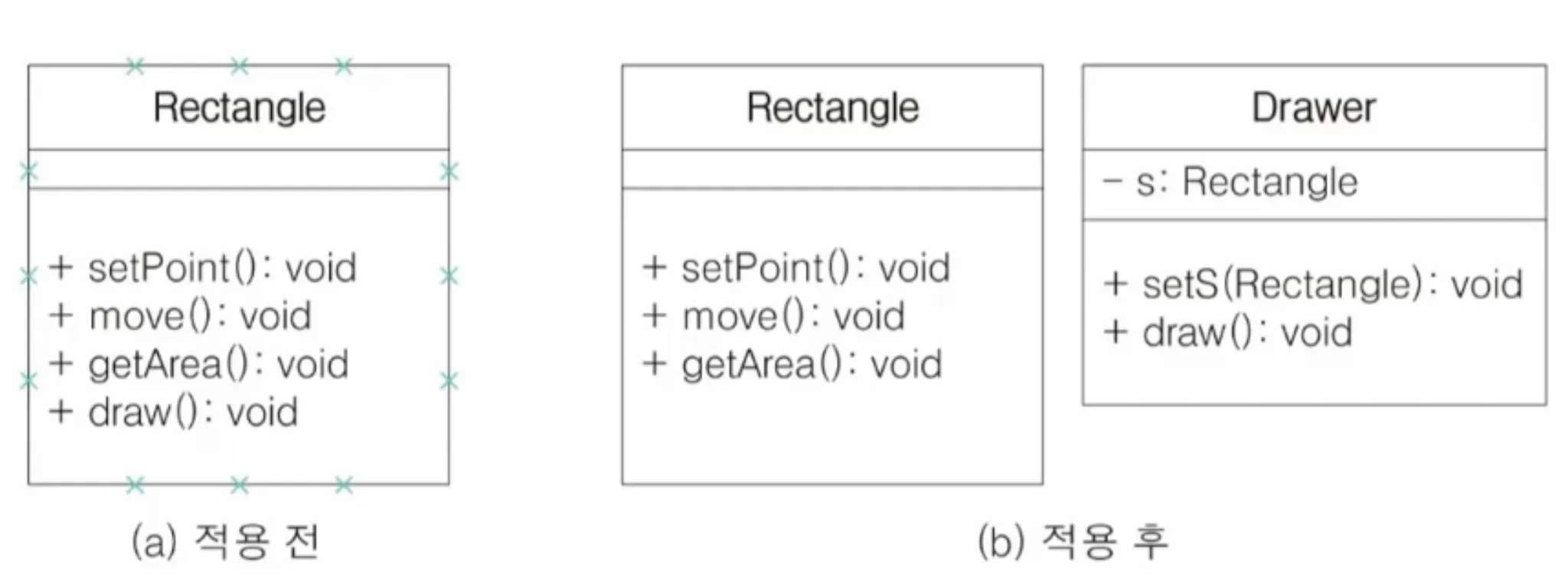
5.2. 개방 폐쇄의 원칙 - OCP
•
클래스가 확장에 열려 있고, 수정에 닫혀 있어야 함
•
새로운 기능을 추가하면서도 기존 코드를 수정하지 않아도 됨
•
예시)
◦
Rectangle → Shape (Rectagle / Circle)
5.3. 리스코프 교체(치환)의 원칙 - LSP
•
부모 유형의 객체는 자식 유형의 객체로 언제든 교체 가능해야 함
•
LSP가 만족되면 새로운 자식 클래스 추가할 때 기존 코드이 수정이 필요 없음
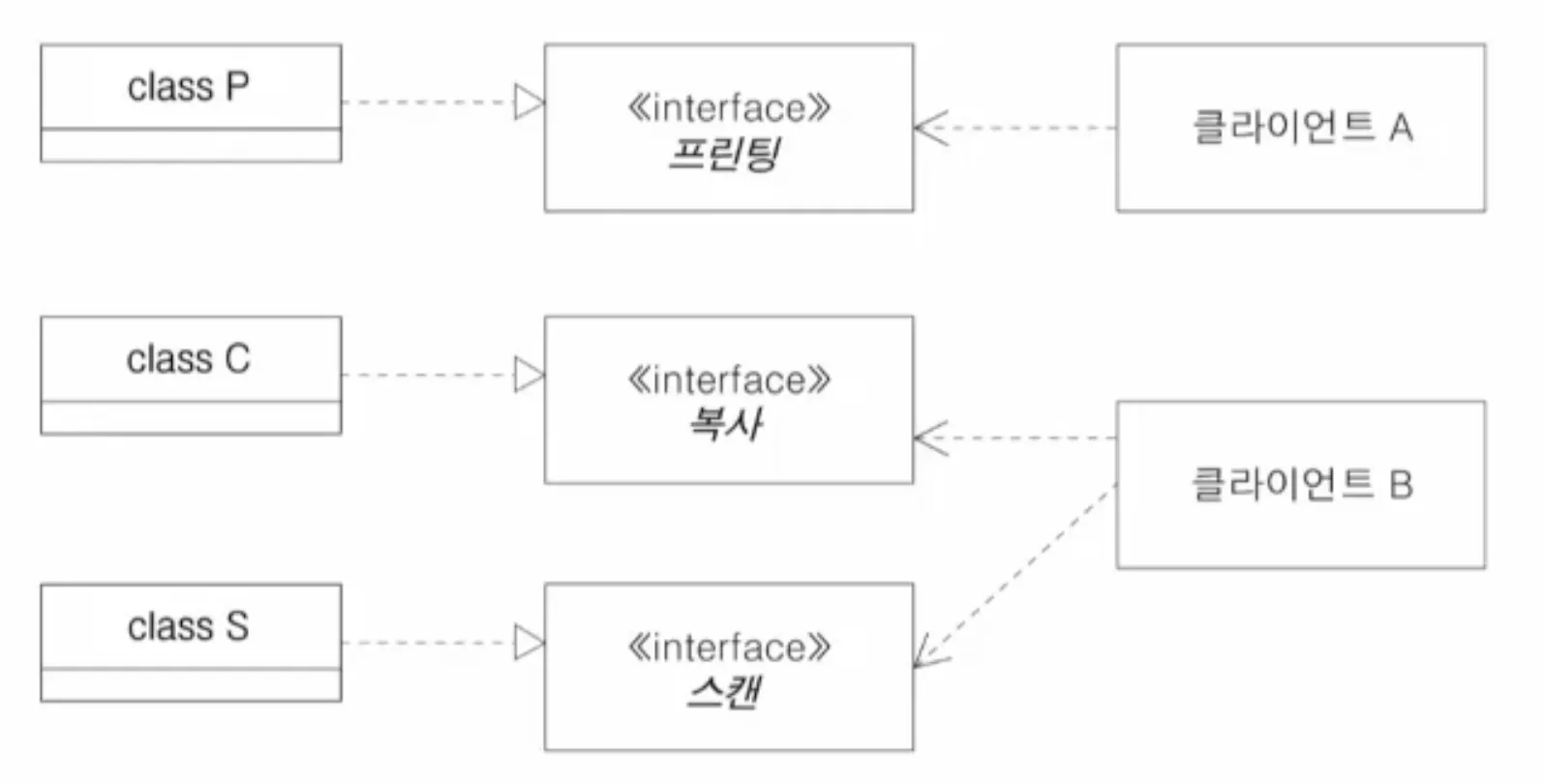
5.4. 인터페이스 분리의 원칙 - ISP
•
하나의 큰 범용 인터페이스가 아닌 작고 특화된 여러 인터페이스로 나누어 설계
◦
ISP 만족 X → 사용하지 않는 인터페이스가 바뀔때도 클라이언트에게 소프트웨어 재배포 필요
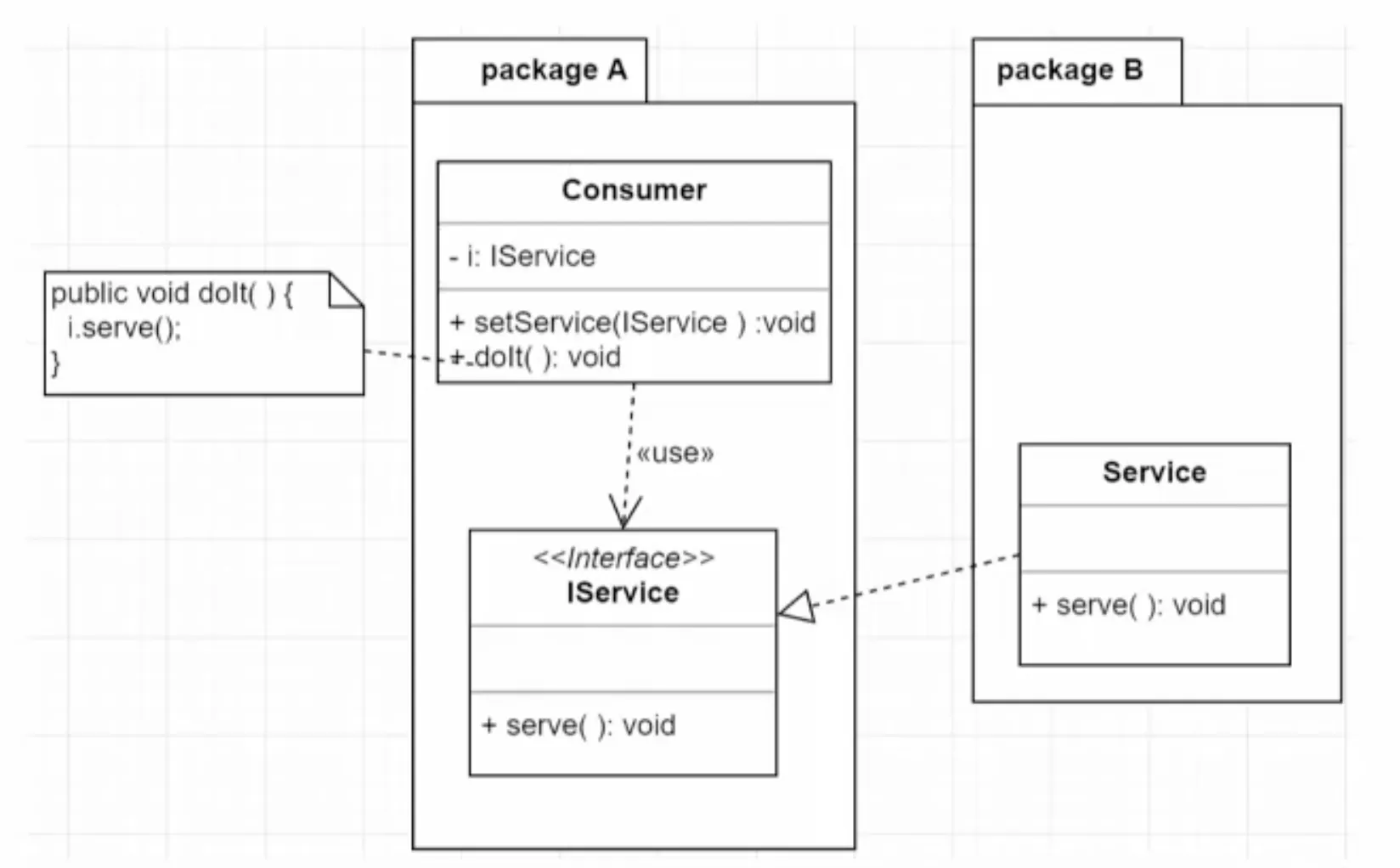
5.4. 의존 관계 역전의 원칙 - DIP
•
구체적 저수준의 사물(구체 클래스)이 아닌 추상적 고수준의 개념(인터페이스)에 의존
•
실제 작업을 수행하는 저수준 구체 클래스는 변경되기 쉬움